在智算平台上进行 NCCL 测试
NCCL(NVIDIA Collective Communications Library)是 NVIDIA 开发的一个用于在多个 GPU 之间进行高效通信的库,它可以在实例内或实例间实现多个 GPU 的快速通信。
本文旨在介绍如何在智算平台上进行 NCCL 测试。
操作步骤
-
参考前文内容,创建分布式训练任务,在弹出的创建训练任务页面,按如下要求配置各项参数。
-
任务信息要求如下:
-
任务类型:选择 Pre-train。 -
框架:选择 MPI。 -
镜像:选择基础镜像下的 NCCL,并选择相应版本。 -
启动命令:请参考下文,各参数含义可参考附录内容。 -
其他参数保持默认,无需进行配置即可。
-
-
计算资源要求如下:
-
资源组:根据实际情况,选择公共资源池或我的资源组,选择 8 卡的 GPU 资源,节点数量设置为1或2。
-
-
-
等待分布式训练任务状态为
已完成,点击任务名称/ID,进入其详情页面。 -
在任务详情页面,选择日志页签,即可查看节点间进行的 NCCL all reduce 通信测试结果。
示例 1:单节点 8 卡
启动命令:
mpirun \
--allow-run-as-root \
-report-bindings \
-x NCCL_SOCKET_IFNAME=eth0 \
-x NCCL_IB_HCA=mlx5 \
-x NCCL_DEBUG=INFO \
-x NCCL_IB_DISABLE=0 \
-x NCCL_NVLS_ENABLE=1 \
-N 1 \
-n 1 \
--bind-to none \
-mca btl_base_verbose 100 \
-mca orte_base_help_aggregate 0 \
-mca btl_openib_allow_ib 1 \
-mca btl_openib_warn_default_gid_prefix 0 \
/opt/nccl-tests/build/all_reduce_perf -b 1G -e 1G -f 2 -g 8单节点进行的 NCCL all reduce 通信测试结果:算法带宽为 462.104。
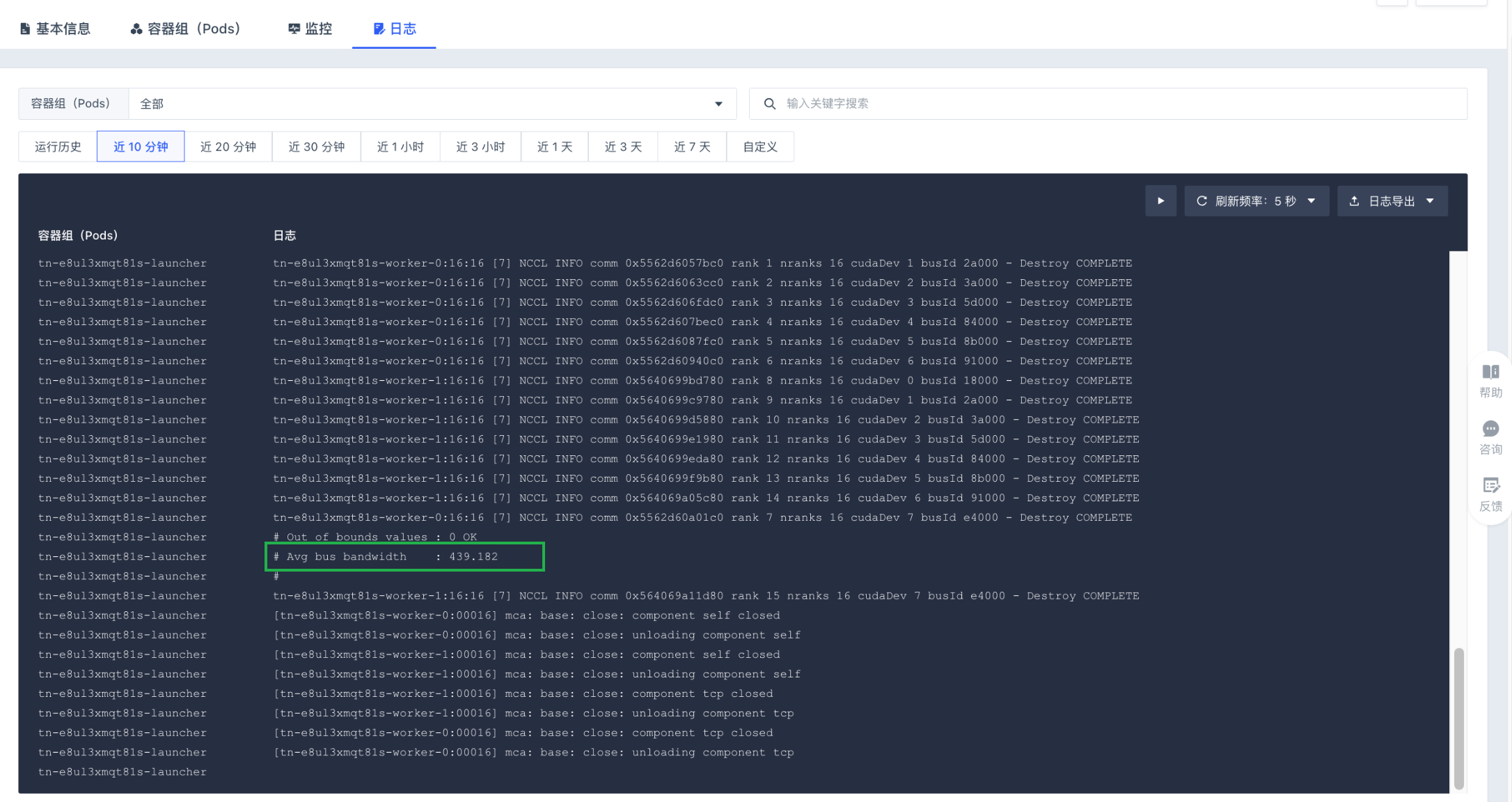
示例 2:2 节点,每节点 8 卡(启用 nvlink)
启动命令:
mpirun \
--allow-run-as-root \
-report-bindings \
-x NCCL_SOCKET_IFNAME=eth0 \
-x NCCL_IB_HCA=mlx5 \
-x NCCL_DEBUG=INFO \
-x NCCL_IB_DISABLE=0 \
-x NCCL_NVLS_ENABLE=1 \
-N 1 \
-n 2 \
--bind-to none \
-mca btl_base_verbose 100 \
-mca orte_base_help_aggregate 0 \
-mca btl_openib_allow_ib 1 \
-mca btl_openib_warn_default_gid_prefix 0 \
/opt/nccl-tests/build/all_reduce_perf -b 1G -e 1G -f 2 -g 8在启用 nvlink 的情况下,2 节点间进行的 NCCL all reduce 通信测试结果:算法带宽为 440.435。
示例 3:2 节点,每节点 8 卡(不启用 nvlink,多进程)
不启用 nvlink,只采用 NCCL,并采用多进程的方式,同时调整部分参数。
启动命令:
mpirun \
--allow-run-as-root \
-report-bindings \
-x NCCL_SOCKET_IFNAME=eth0 \
-x NCCL_IB_HCA=mlx5 \
-x NCCL_DEBUG=INFO \
-x NCCL_IB_DISABLE=0 \
-x NCCL_NVLS_ENABLE=0 \
-N 8 \
-n 2 \
--bind-to none \
-mca btl_base_verbose 1 \
-mca orte_base_help_aggregate 0 \
-mca btl_openib_allow_ib 1 \
-mca btl_openib_warn_default_gid_prefix 0 \
/opt/nccl-tests/build/all_reduce_perf -b 1G -e 10G -f 2 -n 100 -g 1在不启用 nvlink 且多进程的情况下,2 节点间进行的 NCCL all reduce 通信测试结果:算法带宽为 346.504。
示例 4:2 节点,每节点 8 卡( 不启用 nvlink,单进程)
不启用 nvlink,只采用 NCCL,并采用单进程的方式,同时调整部分参数。
启动命令:
mpirun \
--allow-run-as-root \
-report-bindings \
-x NCCL_SOCKET_IFNAME=eth0 \
-x NCCL_IB_HCA=mlx5 \
-x NCCL_DEBUG=INFO \
-x NCCL_IB_DISABLE=0 \
-x NCCL_NVLS_ENABLE=0 \
-N 1 \
-n 2 \
--bind-to none \
-mca btl_base_verbose 1 \
-mca orte_base_help_aggregate 0 \
-mca btl_openib_allow_ib 1 \
-mca btl_openib_warn_default_gid_prefix 0 \
/opt/nccl-tests/build/all_reduce_perf -b 1G -e 10G -f 2 -n 100 -g 8在不启用 nvlink 且单进程的情况下,2 节点间进行的 NCCL all reduce 通信测试结果:算法带宽为 316.771。
附录
创建分布式任务时,设定的启动命令,主要是使用 mpirun 命令启动一个 MPI 的并行计算程序,运行 NCCL 提供的 all_reduce_perf 性能测试工具,各参数的含义如下:
-
mpirun:MPI 的命令行工具,用于运行 MPI 应用程序。 -
--allow-run-as-root:表示允许以 root 用户身份运行 MPI 程序。 -
-report-bindings:表示报告每个进程绑定的 CPU 核心信息,便于调试和性能分析。 -
-x NCCL_SOCKET_IFNAME=eth0:用于设置环境变量NCCL_SOCKET_IFNAME,指定使用的网络接口,此处为eth0,用于网络通信。 -
-x NCCL_IB_HCA=mlx5:用于设置环境变量NCCL_IB_HCA,指定使用的 InfiniBand HCA(主机通道适配器),此处为mlx5。通配所有 mlx5 的网卡,比如 mlx5_0, mlx5_1。 -
-x NCCL_DEBUG=INFO:用于设置环境变量NCCL_DEBUG,启用 NCCL 的调试信息,级别为INFO,用于输出调试日志。 -
-x NCCL_IB_DISABLE=0:用于设置环境变量NCCL_IB_DISABLE,将其设置为0表示启用 InfiniBand。 -
-x NCCL_NVLS_ENABLE=1:设置环境变量NCCL_NVLS_ENABLE,启用NCCL NVLink支持。请提前确认机器是否有 NVLINK,可咨询服务器厂商或者到服务器官网查询。 -
-N 1:表示每个节点启动 1 个进程。 -
-n 2:表示启动总共 2 个进程,数量与节点数相同。请注意选择合适的节点(pod)数量。 -
--bind-to none:表示不对进程进行 CPU 绑定,允许操作系统自由调度进程到任何可用的 CPU 核心。 -
-mca btl_base_verbose 100:用于设置 Open MPI 的 MCA 参数,启用更详细的 BTL(Byte Transfer Layer)调试信息,用于性能分析。 -
-mca orte_base_help_aggregate 0:表示禁用错误信息的聚合,确保每个进程都能单独输出错误信息,便于调试。 -
-mca btl_openib_allow_ib 1:表示允许使用 InfiniBand 进行通信。 -
-mca btl_openib_warn_default_gid_prefix 0:表示禁用警告,指示 Open MPI 使用默认的 GID 前缀。 -
/opt/nccl-tests/build/all_reduce_perf:指定要执行的程序,这里是 NCCL 提供的性能测试工具all_reduce_perf。 -
-b 1G -e 1G -f 2 -g 8:均为传递给all_reduce_perf的参数:-
-b 1G:设置最小数据大小为 1GB。 -
-e 1G:设置最大数据大小为 1GB。 -
-f 2:设置数据量每次翻一倍。 -
-g 8:设置每个进程的 GPU 数量为 8。与服务器上的 GPU 数量相关,单节点 8 卡选择 8 卡计算。
-
| 说明 |
|---|
|
-
更多介绍可参考 NCCL 相关内容。