启动命令说明
vLLM 部署方式
平台内置的标准启动命令示例:
python3 -m vllm.entrypoints.openai.api_server --trust-remote-code --enable-prefix-caching --disable-log-requests --model {ENV_MODEL_PATH} --gpu-memory-utilization 0.95 -tp {ENV_SPEC_GPU_COUNT} -pp {ENV_NODE_NUM} --port {ENV_SERVER_PORT} --served-model-name {ENV_MODEL_NAME} --max-model-len 8192命令行说明:
-
python3 -m vllm.entrypoints.openai.api_server:使用 Python 运行 vLLM 的api_server模块,启动与 OpenAI API 兼容的推理服务器,接受客户端推理请求。 -
--trust-remote-code:允许加载远程代码,适用于从外部(如 Hugging Face)获取模型或组件,当ENV_MODEL_PATH指向一个远程模型(如 Hugging Face 的 "meta-llama/Llama-2-7b-hf"),且该模型包含非标准代码时,--trust-remote-code允许 vLLM 下载并执行这些代码。 -
--enable-prefix-caching:启用前缀缓存,优化推理性能,减少计算开销。 -
--disable-log-requests:禁用 API 请求日志,适合生产环境,减少日志输出以提高效率。 -
--model {ENV_MODEL_PATH}:指定模型路径或标识符,从环境变量ENV_MODEL_PATH获取,其值可参考附录中命令行各值来源说明。 -
--gpu-memory-utilization 0.95:设置 GPU 内存使用率,占用 95% 的可用 GPU 内存,优化性能并保留少量内存以确保稳定性。 -
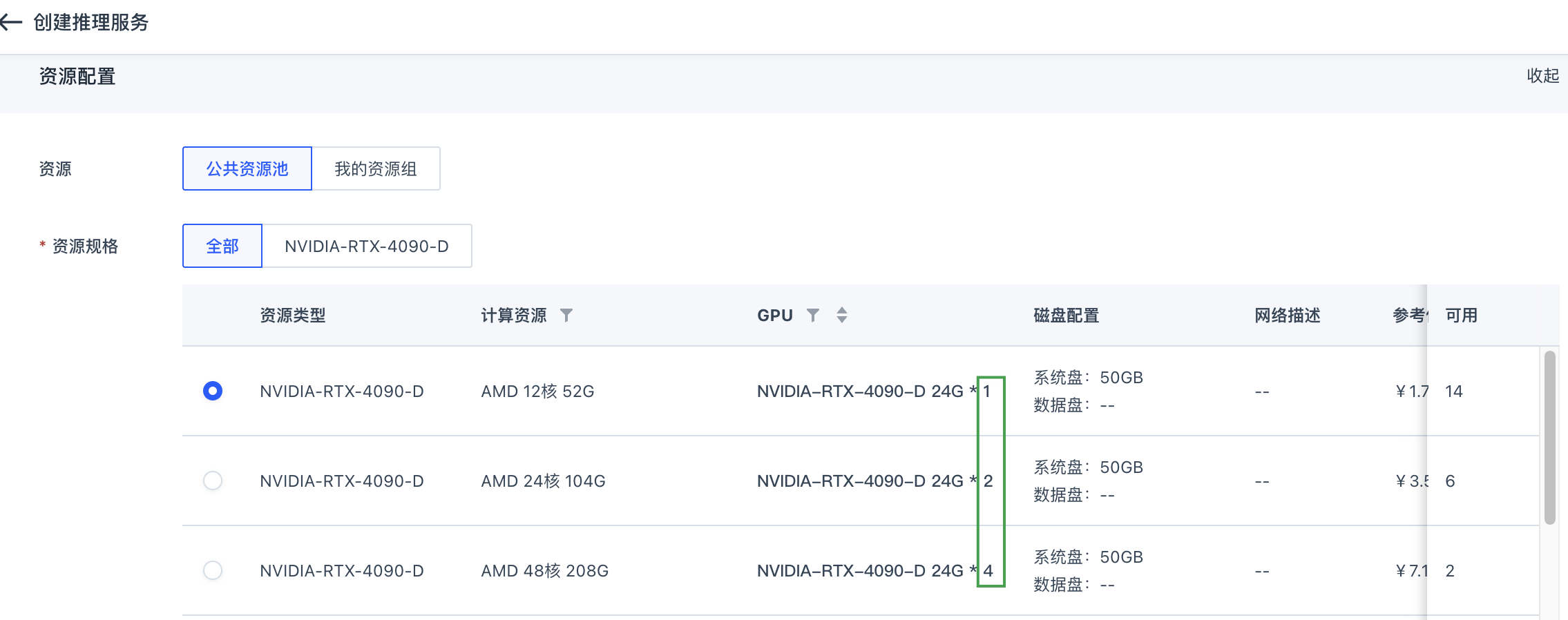
-tp {ENV_SPEC_GPU_COUNT}:配置张量并行(tensor parallelism),将模型权重和计算分配到多个 GPU,值从环境变量ENV_SPEC_GPU_COUNT获取,其值可参考附录中命令行各值来源说明。 -
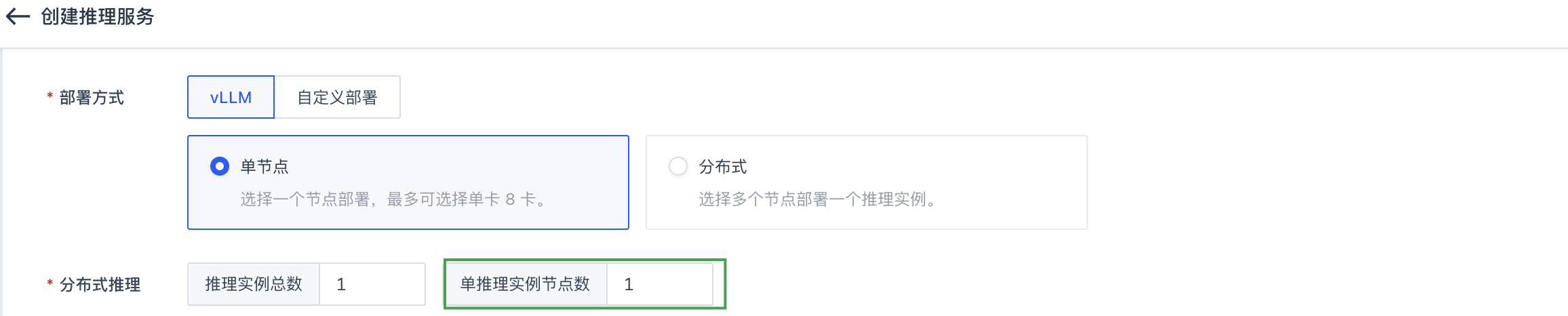
-pp {ENV_NODE_NUM}:配置流水线并行(pipeline parallelism),将模型计算阶段分配到多个节点,值从环境变量ENV_NODE_NUM获取,其值可参考附录中命令行各值来源说明。 -
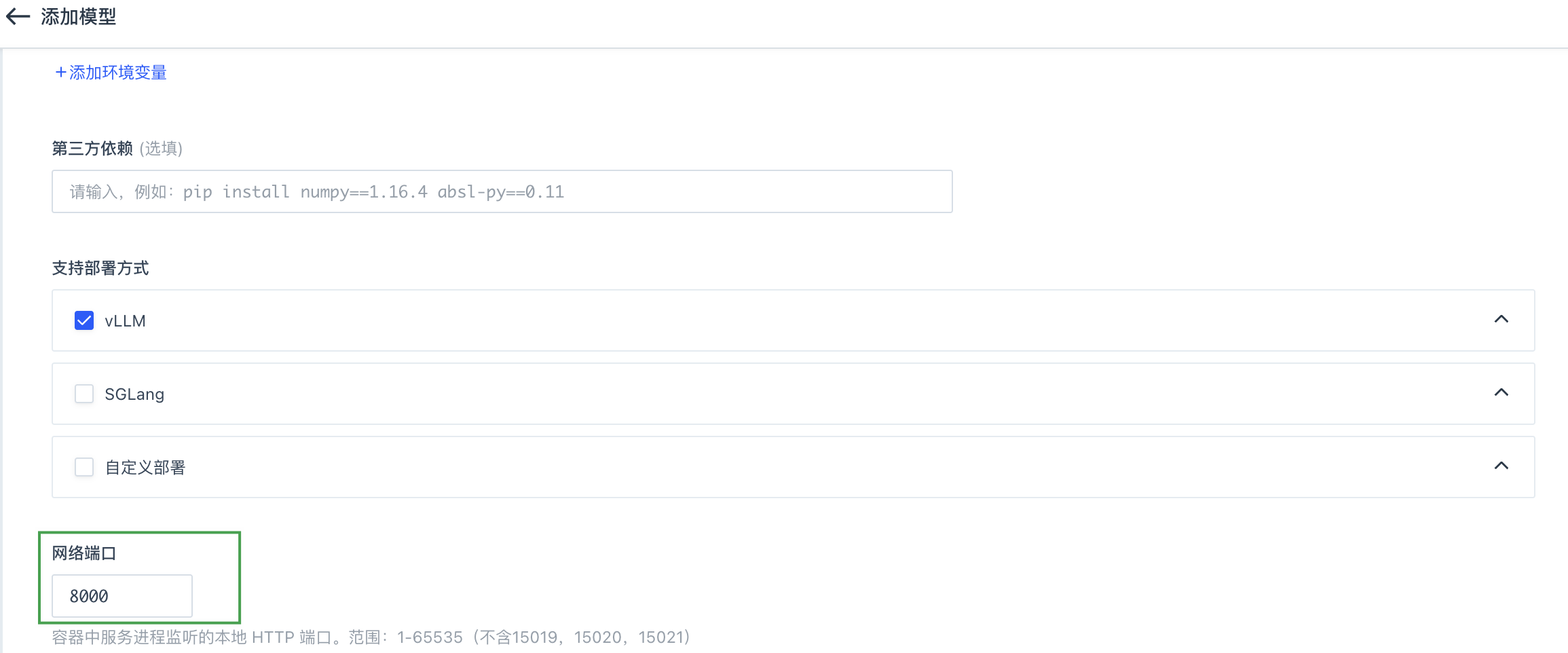
--port {ENV_SERVER_PORT}:指定 API 服务器监听的网络端口,从环境变量ENV_SERVER_PORT获取,其值可参考附录中命令行各值来源说明。 -
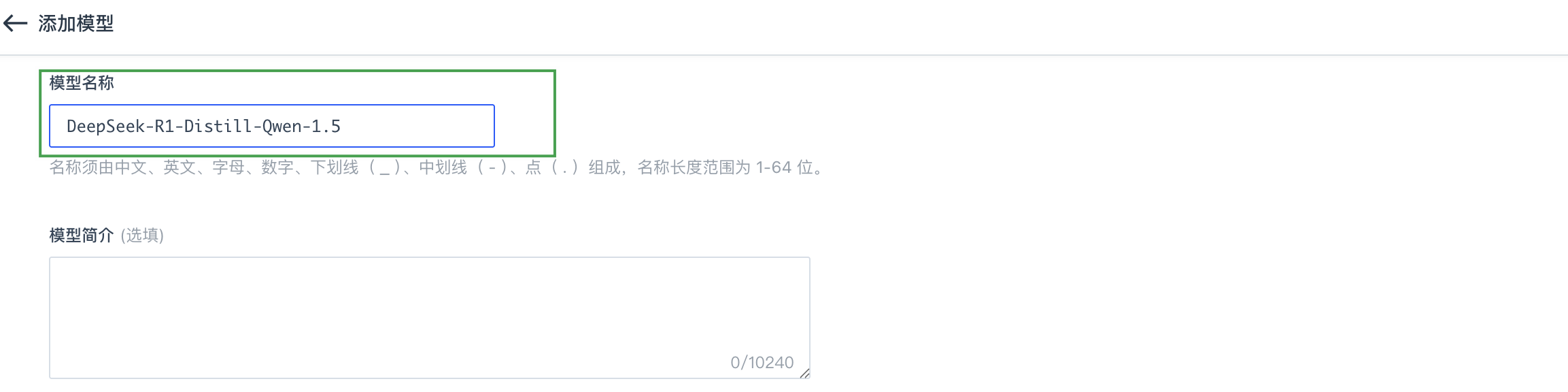
--served-model-name {ENV_MODEL_NAME}:定义 API 暴露的模型名称,从环境变量ENV_MODEL_NAME获取,其值可参考附录中命令行各值来源说明。 -
--max-model-len 8192:设置模型处理的单次推理最大序列长度(输入+输出),固定为8192token。 -
更多 vLLM 命令详细介绍,可参考其官方网站。
SGLang 部署方式
平台内置的标准启动命令示例:
python3 -m sglang.launch_server --model-path {ENV_MODEL_PATH} --served-model-name {ENV_MODEL_NAME} --tp {ENV_INSTANCE_GPU_COUNT} --dist-init-addr $LWS_LEADER_ADDRESS:5000 --nnodes $LWS_GROUP_SIZE --node-rank $LWS_WORKER_INDEX --trust-remote-code --host 0.0.0.0 --port {ENV_SERVER_PORT} --show-time-cost --enable-metrics --context-length 8192命令行说明:
-
python3 -m sglang.launch_server:使用 Python 运行 SGLang 的launch_server模块,启动一个推理服务器。 -
--model-path {ENV_MODEL_PATH}:指定模型路径,从环境变量ENV_MODEL_PATH获取,其值可参考附录中命令行各值来源说明。 -
--served-model-name {ENV_MODEL_NAME}:定义 API 暴露的模型名称,从环境变量ENV_MODEL_NAME获取,其值可参考附录中命令行各值来源说明。 -
--tp {ENV_INSTANCE_GPU_COUNT}:配置张量并行(tensor parallelism),将模型权重和计算分配到多个 GPU,值从环境变量ENV_INSTANCE_GPU_COUNT获取,其值可参考附录中命令行各值来源说明。 -
--dist-init-addr $LWS_LEADER_ADDRESS:5000:指定分布式初始化的领导节点 IP 和端口,从LWS_LEADER_ADDRESS获取(默认:127.0.0.1),用于多节点通信协调。 -
--nnodes $LWS_GROUP_SIZE:指定分布式推理任务涉及的节点总数,值从环境变量LWS_GROUP_SIZE获取,默认为1。 -
--node-rank $LWS_WORKER_INDEX:指定当前节点的排名,从LWS_WORKER_INDEX获取(默认:0),标识分布式系统中当前节点的唯一索引 -
--trust-remote-code:允许加载远程代码,适用于从外部(如 Hugging Face)获取模型或组件。当ENV_MODEL_PATH指向远程模型,且模型包含非标准代码时,启用此选项以允许 SGLang 下载并执行这些代码。 -
--host 0.0.0.0:设置服务器监听的 IP 地址,0.0.0.0表示监听所有可用网络接口,允许外部客户端访问推理服务器。 -
--port {ENV_SERVER_PORT}:指定 API 服务器监听的网络端口,从环境变量ENV_SERVER_PORT获取,其值可参考附录中命令行各值来源说明。 -
--show-time-cost:启用推理耗时统计,输出每次请求的处理时间,便于调试和性能监控。 -
--enable-metrics:启用性能指标收集,记录服务器运行时的指标(如请求延迟、吞吐量等),便于监控和优化。 -
--context-length 8192:设置模型最大上下文长度(输入+输出),固定为8192token,定义单次推理的序列上限。 -
更多 SGLang 命令详细介绍,可参考其官方网站。
附录
命令行各值来源:
| 变量值 | 说明 |
|---|---|
{ENV_MODEL_PATH} |
为用户在进行添加模型操作时,设置
|
{ENV_SPEC_GPU_COUNT} |
为用户在进行模型部署操作时,设置
|
{ENV_NODE_NUM} |
为用户在进行模型部署操作时,设置
|
{ENV_SERVER_PORT} |
为用户在进行添加模型操作时,设置
|
{ENV_MODEL_NAME} |
为用户在进行添加模型操作时,设置
|
{ENV_INSTANCE_GPU_COUNT} |
为单个实例 GPU 数,其值为 单实例节点数:即用户在进行模型部署操作时,设置 GPU 卡数:即用户在进行模型部署操作时,设置 |