部署模型
模型部署即创建推理服务。推理服务是指对每一个推理请求同步给出推理结果的在线服务,AI 计算平台为用户提供推理服务实例全生命周期管理,推理实例可在线扩容、缩容,推理实例实时监控,推理日志检索查询等功能,方便用户对各种 AI 业务进行可靠性管理。
用户可在模型广场使用已有的预置模型一键部署模型,也可上传私有模型、使用自定义推理镜像部署模型,从而以较低的资源成本获取高并发且稳定的在线模型服务。
从模型广场进行部署
前提条件
已经获取控制台账户和密码。
操作步骤
-
登录控制台。
-
在左侧导航栏,选择模型广场,进入模型广场页面。
-
在模型广场页面,在搜索框内输入关键字段,筛选出待使用的模型,点击模型部署。
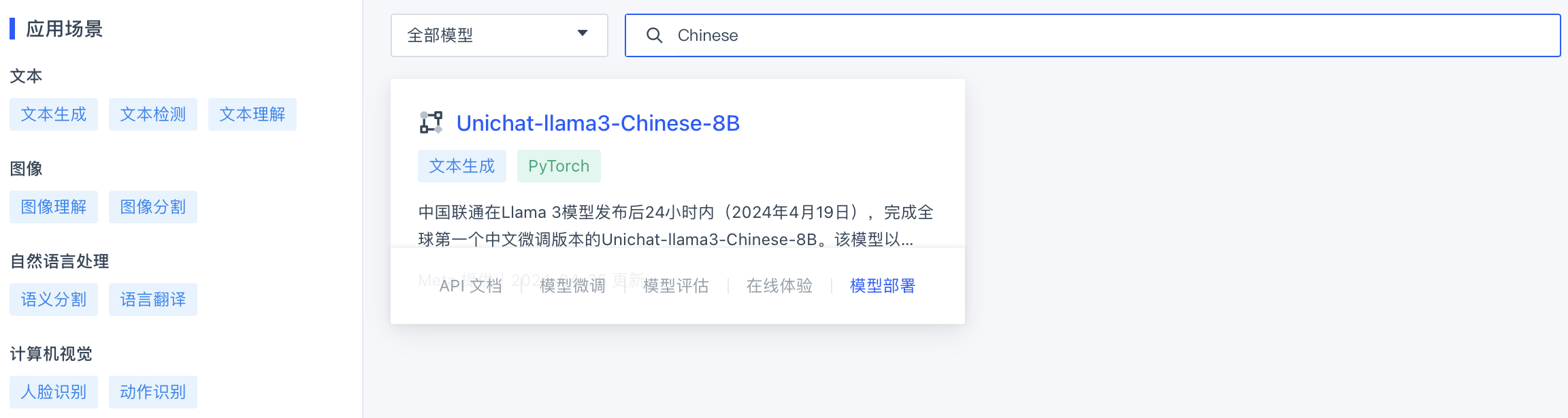
-
在弹出的创建推理服务窗口中,参考以下说明,配置各项参数。
参数 说明 服务名称
选填项,当前推理服务的名称,由用户自定义。
模型来源
默认为模型库。
模型名称
用户在模型广场选定的模型名称,系统自动获取。
部署方式
根据用户在模型广场中选定的模型,系统将自动获取相应的部署方式。用户可根据实际需要选择单节点或分布式。
-
单节点:针对单个节点即可部署和启动的模型,最多可选择 8 卡。 -
分布式:若当前模型单个节点无法启动,可选择多个节点部署一个推理实例。
数量
用户可根据实际需要,设置推理实例总数和单推理实例节点数。
-
推理实例总数:当前创建的推理服务中所包含推理实例(副本)的个数。 -
单推理实例节点数:每个推理实例(副本)中所包含节点数。
API Key
是否为推理服务创建 API Key。目前,仅大语言模型支持创建 API Key,OCR 模型暂不支持。
更多配置
注意 仅部分模型支持更多配置的修改。
展开更多配置,可设置如下参数:
-
环境变量:用户添加相应环境变量后,系统会构建相应计算环境,平台已提前预置了环境变量。 -
启动命令:根据所选模型启动代码所在路径,系统生成相应模型推理的启动命令。 -
第三方依赖:用于加载镜像中不包含的环境依赖。 -
网络端口:容器中服务进程监听的本地 HTTP 端口。范围:1~65535(不含15019,15020,15021)。
资源配置
针对当前模型进行在线推理所需的资源配置,用户可根据实际情况选择相应的资源类型及配置。
-
-
点击确定,等待服务创建完成。创建成功的服务,其状态应为
活跃,且服务状态为健康。点击服务名称/ID,即可进入其详情页面,查看相应模型推理结果。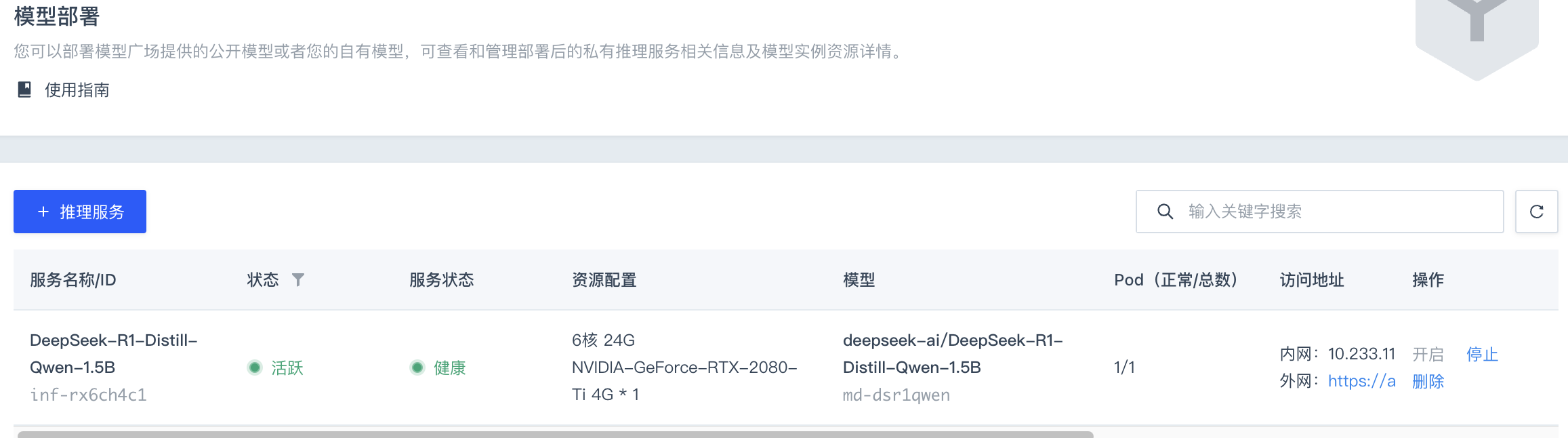
利用私有模型进行部署
前提条件
-
已经获取控制台账户和密码。
-
模型管理列表已存在可使用的模型,即已成功添加模型,且其状态为
已就绪。
操作步骤
-
登录控制台。
-
在左侧导航栏,选择模型部署,进入推理服务列表页面,点击 + 推理服务。
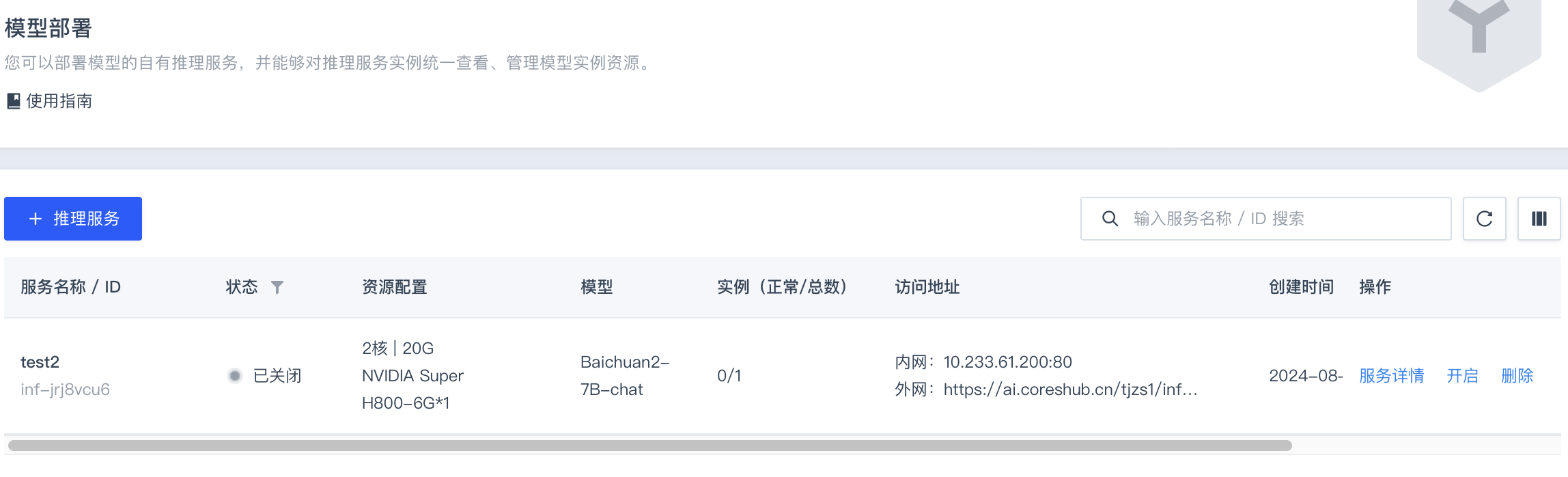
-
在弹出的创建推理服务页面中配置各项参数,然后点击确定。
参考以下说明进行配置。
参数 说明 服务名称
选填项,当前推理服务的名称,由用户自定义。
模型来源
选择自定义模型。
模型名称
用户添加模型时已经提前设置好的名称,系统自动获取。用户直接选择指定模型即可。
部署方式
根据用户选定的模型,系统将自动获取相应的部署方式。若有多种部署方式,根据实际需要选择即可。同时,用户也可选择单节点或分布式。
-
单节点:针对单个节点即可部署和启动的模型,最多可选择 8 卡。 -
分布式:若当前模型单个节点无法启动,可选择多个节点部署一个推理实例。
数量
用户可根据实际需要,设置推理实例总数和单推理实例节点数。
-
推理实例总数:当前创建的推理服务中所包含推理实例(副本)的个数。 -
单推理实例节点数:每个推理实例(副本)中所包含节点数。
API Key
是否为推理服务创建 API Key。目前,仅大语言模型支持创建 API Key,OCR 模型暂不支持。
更多配置
仅在添加模型时开启了允许用户部署中修改按钮,才会有该选项。
支持用户对
环境变量、启动命令、第三方依赖以及网络端口进行修改。资源配置
针对当前模型部署所需的资源配置,用户可根据实际情况选择相应的资源类型及配置。
-
-
创建成功的服务,其状态应为
活跃,且服务状态为健康。点击服务名称/ID,即可进入其详情页面,查看相应模型推理结果。
模型调用
模型部署成功后,用户可直接调用该模型。