使用 LLaMA Factory 进行模型微调
LLaMA Factory 是一款开源低代码大模型微调框架,集成了业界广泛使用的微调技术,支持通过 Web UI 界面零代码微调模型。本文介绍如何在基石智算平台上,使用 LLaMA Factory 通过 Web UI 进行模型微调。
前提条件
-
已经获取基石智算控制台账户和密码。
-
已完成实名认证且账户余额大于 0 元。
-
存储与数据服务中已创建可用的用户目录。
操作步骤
准备环境和资源
-
登录基石智算控制台,默认进入 AI 计算平台。
-
在左侧导航栏,点击存储与数据服务,选择指定目录,上传数据集到相应用户目录。
本次示例使用 alpaca_zh_demo.json 数据集,其中该数据集需在 dataset_info.json 文件中定义,故 alpaca_zh_demo.json 和 dataset_info.json 均需提前上传至用户目录。
-
在左侧导航栏,点击镜像仓库,选择应用镜像页签。
-
在 LLaMA-Factory 镜像卡片页,点击创建容器实例。

-
进入创建容器实例页面,按照如下要求配置参数,点击创建。
-
资源类型:选择显存较高的 GPU 节点即可。 -
存储与数据:选择上传有数据集的用户目录。 -
镜像:已根据上一步操作,选定为应用镜像下的LLaMA-Factory。 -
其他参数,根据实际情况进行设定即可。
-
-
等待容器实例创建完成,且状态为
运行中。
启动 Web UI
-
在容器实例列表页面,点击更多访问 > web 连接。

-
在 web 连接窗口中,输入如下命令,指定
9001端口用于启动 Web UI。export GRADIO_SERVER_PORT=9001; llamafactory-cli webui
打开 Web UI
-
返回容器实例列表页面,点击更多访问。

-
弹出更多访问信息窗口,点击
9001端口所对应的地址。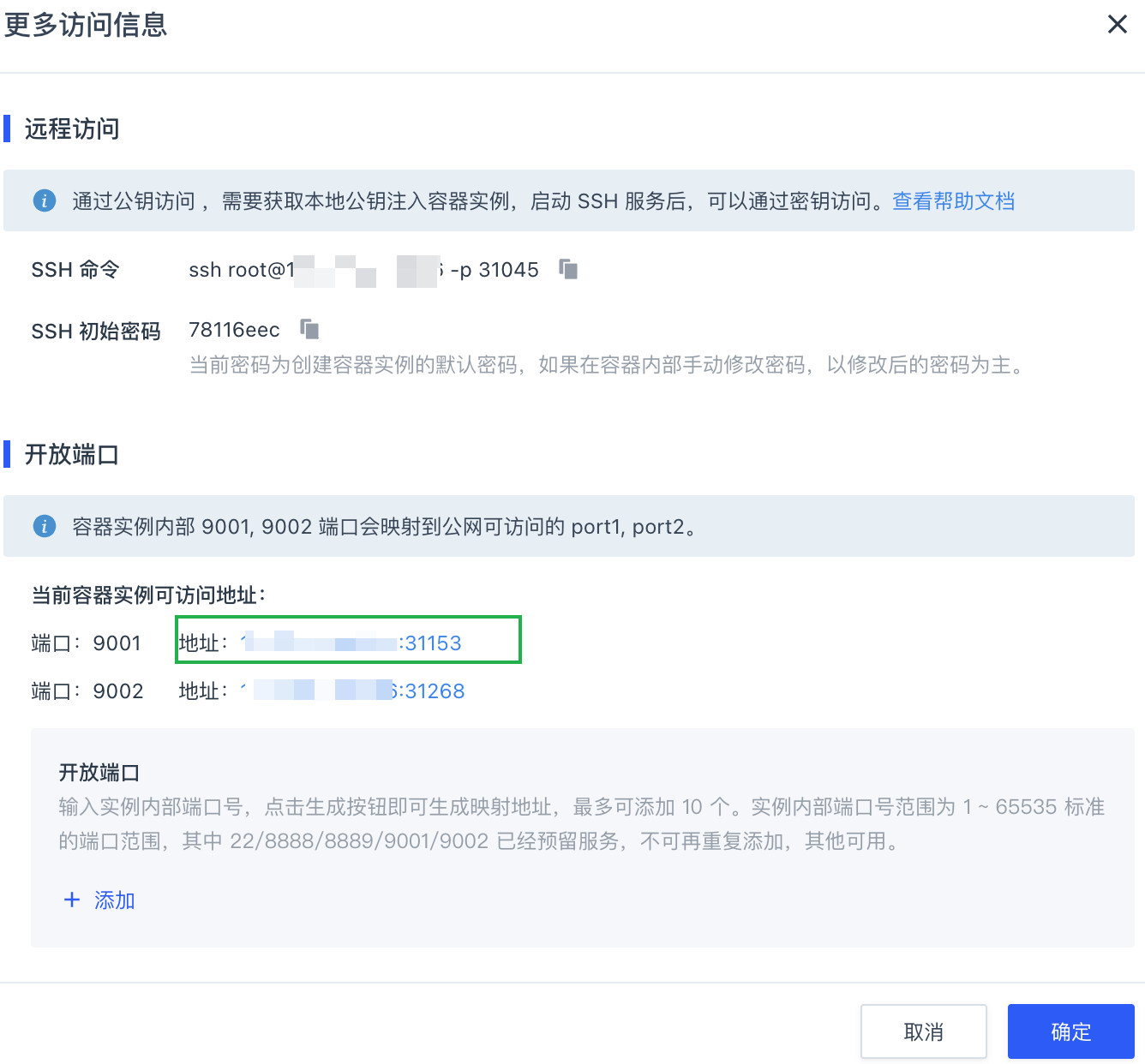
-
即可进入 Web UI 界面。
设置微调参数
-
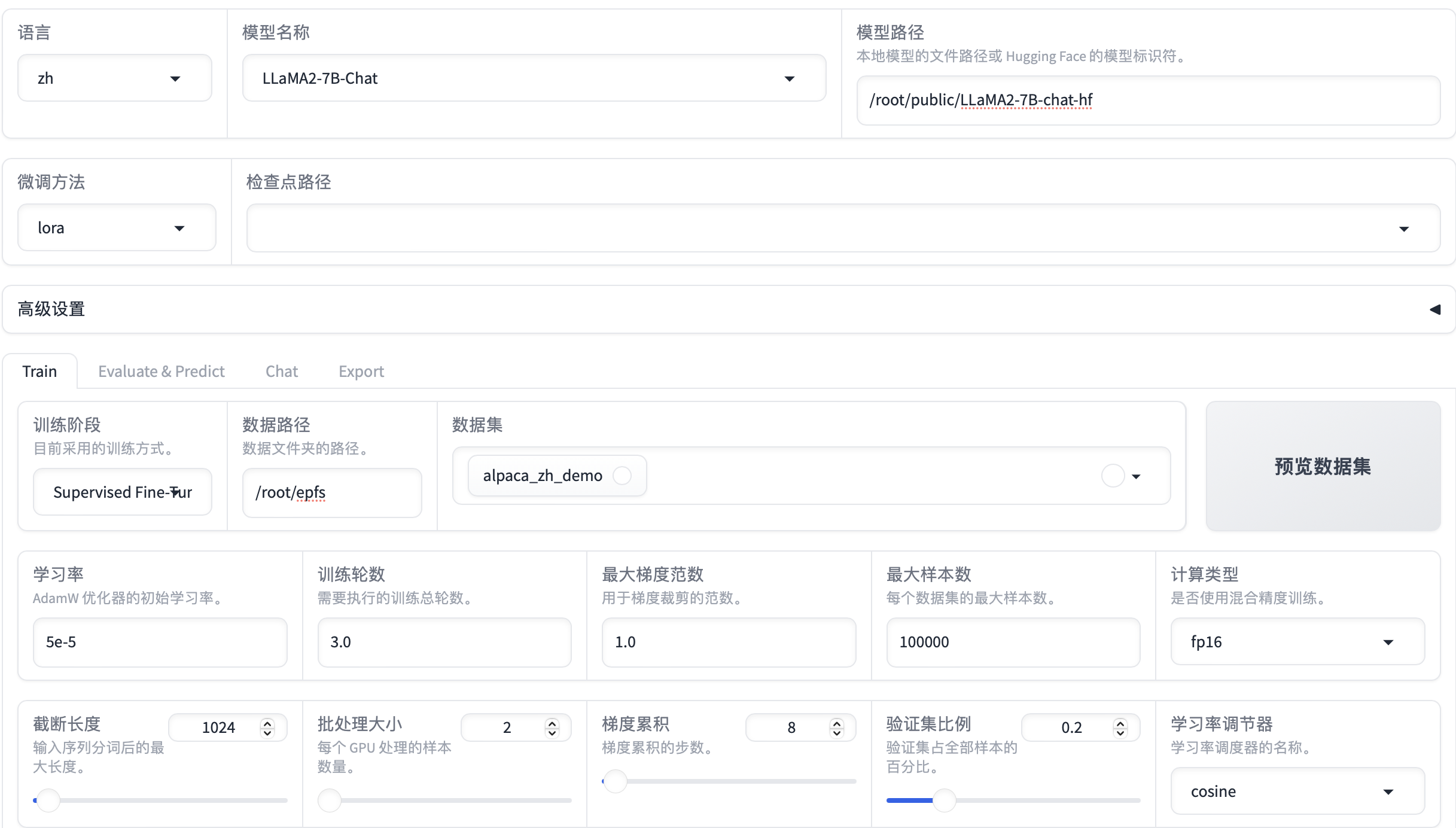
在 Web UI 界面,配置各项参数。
参数 示例取值 说明 语言
zh
-
模型名称
LLaMA2-7B-Chat
-
模型路径
/root/public/LLaMA2-7B-chat-hf
容器实例的
/root/public目录下内置了一些开源模型可供选择,用户也可以选择自己上传的模型。确保模型路径准确即可微调方式
lora
-
LoRA 一种轻量化微调方法,通过在现有的模型权重矩阵中插入低秩矩阵来实现微调,能在很大程度上节省显存。
-
Full 全参数微调,需要更大显存。
-
Freeze 冻结(即不更新)一部分模型的参数,只微调剩余的参数,可有效节省计算资源。
检查点路径
保持默认即可
一般新训练为空即可。若是继续训练,则可设置为之前保存的 checkpoint 路径。
训练阶段
Supervised Fine-Tuning
-
数据路径
/root/epfs
保存微调数据集的文件夹,此处建议使用平台的存储与数据服务功能创建相应的用户目录,需根据实际情况进行修改。
数据集
alpaca_zh_demo
数据路径中需要用到的数据集文件名,根据实际情况进行选择即可。
学习率
保持默认即可。
AdamW 优化器的初始学习率。
训练轮数
保持默认即可。
需要执行的训练总轮数。轮次越多损失越小,对数据学习程度越好。
最大梯度范数
保持默认即可。
用于梯度裁剪的范数。
最大样本数
100000
每个数据集的最大样本数。根据数据集的大小设置。
计算类型
fp16
较新的 GPU,推荐选择
bf16,老旧显卡建议选择fp16。若对精度要求高,则选择fp32。截断长度
保持默认即可。
该参数主要影响对话过程中,上下文的长度。
批处理大小
保持默认即可。
每个 GPU 处理的样本数量。用户需根据 GPU 显存大小合理设置。
梯度累计
保持默认即可。
梯度累积的步数。
验证集比例
0.2
验证集占全部样本的百分比,一般设置为 0.2。
学习率调节器
保持默认即可
-
-
启动微调
-
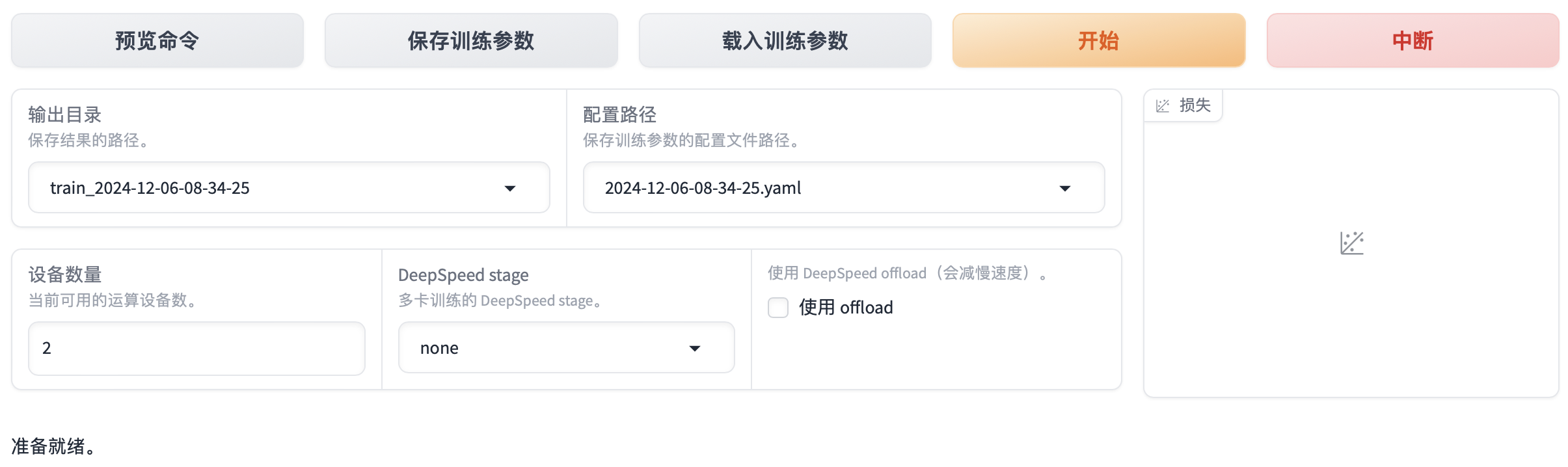
下拉 Web UI 页面,根据实际需要配置输出目录,点击开始。
-
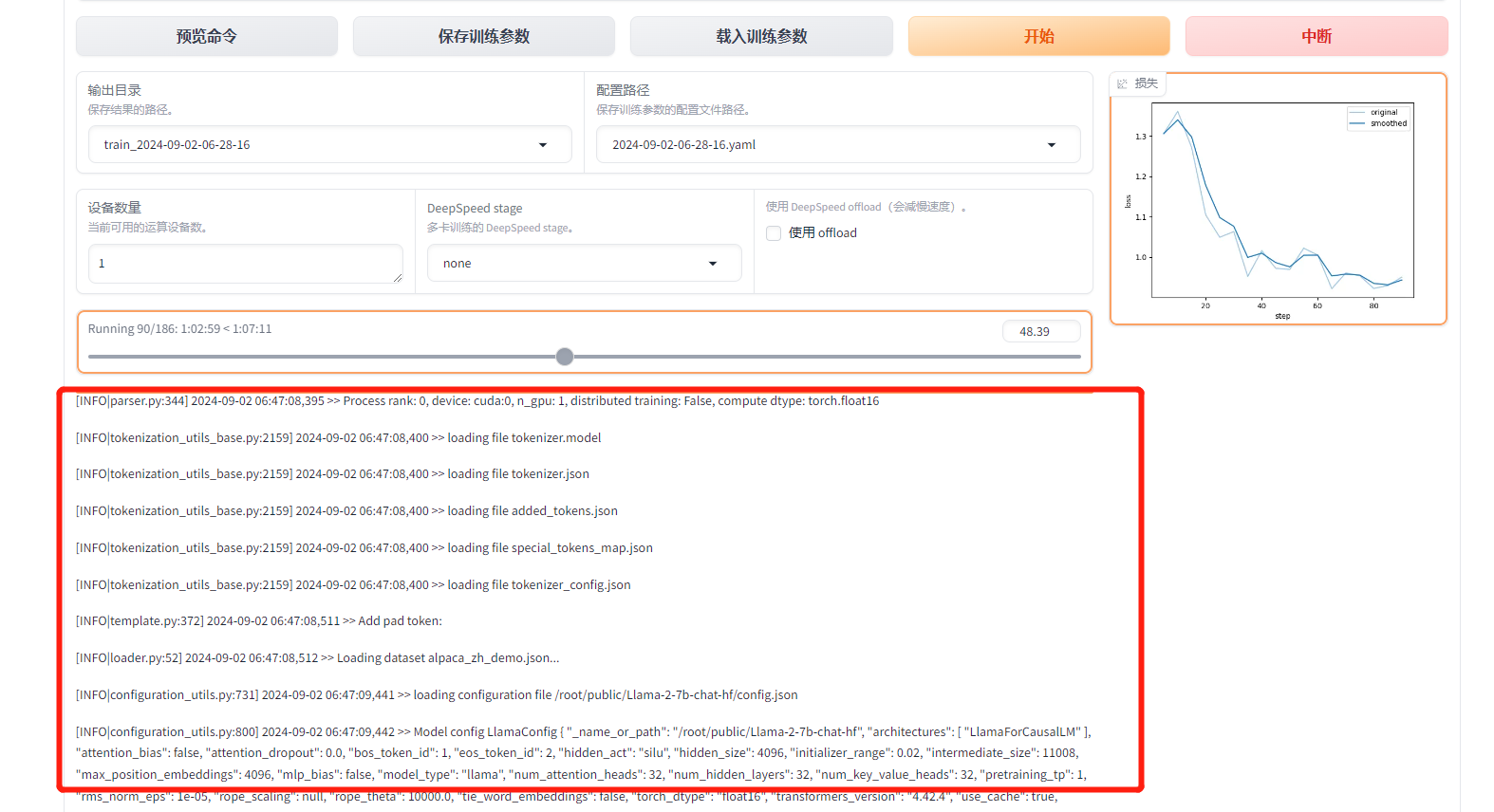
等待模型训练,可在界面观察到训练进度、输出日志和损失曲线,如下图所示。
说明 更多有关 LLaMA Factory 的信息,可参考 LLaMA Factory。