FunAudioLLM 模型的使用
背景信息
FunAudioLLM 是阿里巴巴通义实验室推出的一款开源语音大模型,它包含两个核心模型:SenseVoice 和 CosyVoice。SenseVoice 专注于多语言语音识别、情感辨识和声音事件检测,支持超过 50 种语言,尤其在中文和粤语的识别上表现优异,准确率提升超过 50%。它还能够识别多种情绪和交互事件,如音乐、掌声、笑声、哭声等。CosyVoice 则擅长语音合成,能够根据少量原始音频快速生成模拟音色,包括韵律和情感细节,并支持跨语言合成。
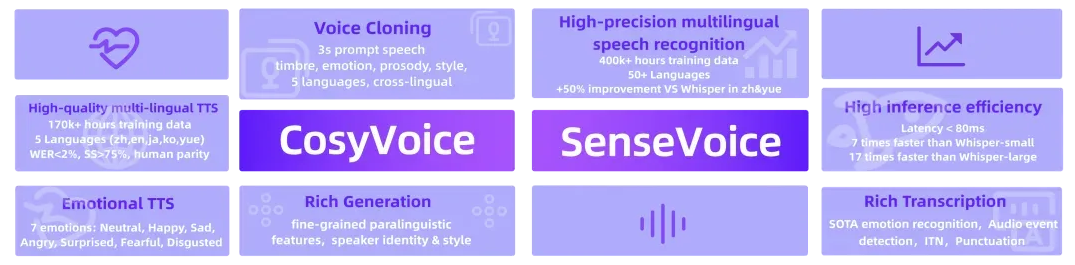
FunAudioLLM 的应用场景非常广泛,如语音到语音翻译、情感语音对话、互动播客和有声读物等。例如,在语音到语音翻译场景中,它可以将中文语音翻译成英文语音,同时保留原说话人的音色和情感色彩。在情感语音对话中,它可以与用户进行带有情绪色彩的交互,提升用户体验。此外,它还可以用于制作互动播客和有声读物,提供丰富多彩的听觉体验。
-
语音翻译:将输入语音翻译成目标语言,并使用目标语言生成语音。
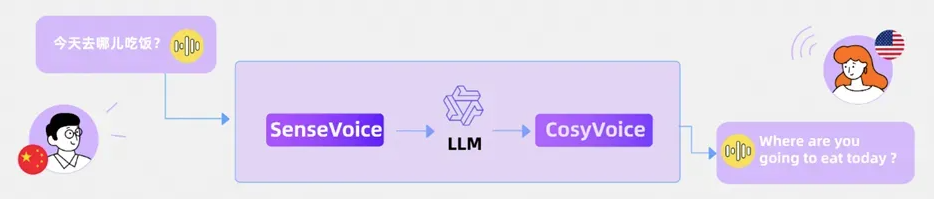
-
情感语音聊天:识别输入语音的情绪和音频事件,并生成与情绪相符的语音。
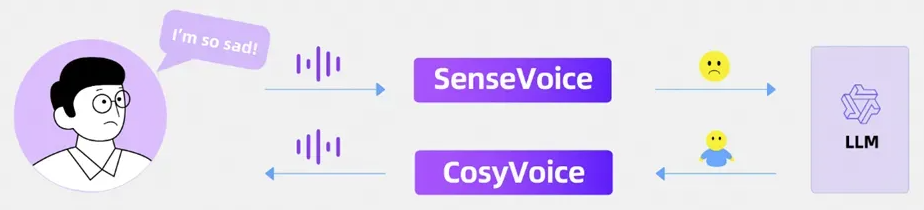
-
交互式播客:根据实时世界知识和内容生成播客脚本,并使用 CosyVoice 合成语音。
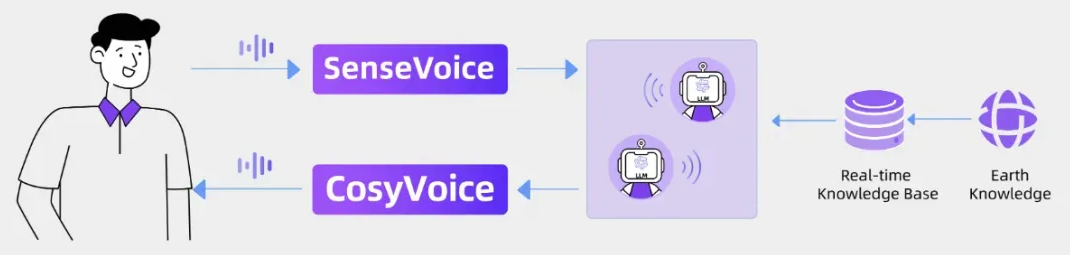
-
有声读物:分析文本中的情感和角色,并使用 CosyVoice 合成具有丰富情感的有声读物。

前提条件
-
已经获取基石智算控制台账户和密码。
-
已完成实名认证且账户余额大于 0 元。
操作步骤
-
登录控制台,默认进入 AI 计算平台。
-
在左侧导航栏,点击镜像仓库,选择应用镜像页签。
-
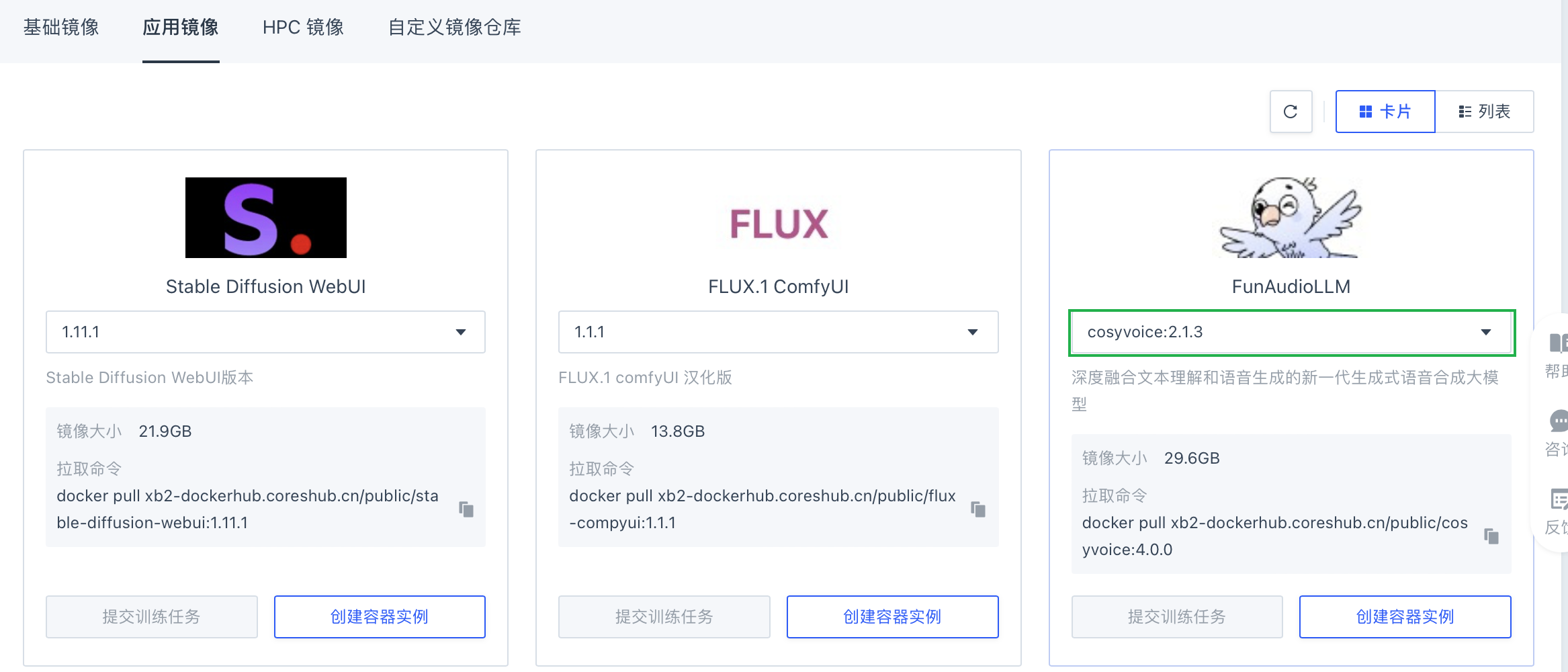
在 FunAudioLLM 卡片页,选择
cosyvoice镜像,点击创建容器实例。说明 此处以 CosyVoice 模型为例。用户也可根据实际需要,选择 SenseVoice 模型。
-
在创建容器实例页面中,根据如下要求配置各项参数,点击创建。
-
资源类型:推荐选择西北二区的 NVIDIA-GeForce-RTX-3090 24G*1 GPU 资源。 -
镜像:已选择上一步选定的应用镜像。 -
其他参数,根据实际情况进行设定即可。
-
-
等待容器实例创建完成,且状态为
运行中,点该实例的更多访问。
-
在弹出的更多访问信息窗口中,点击开放端口
9001所对应的地址。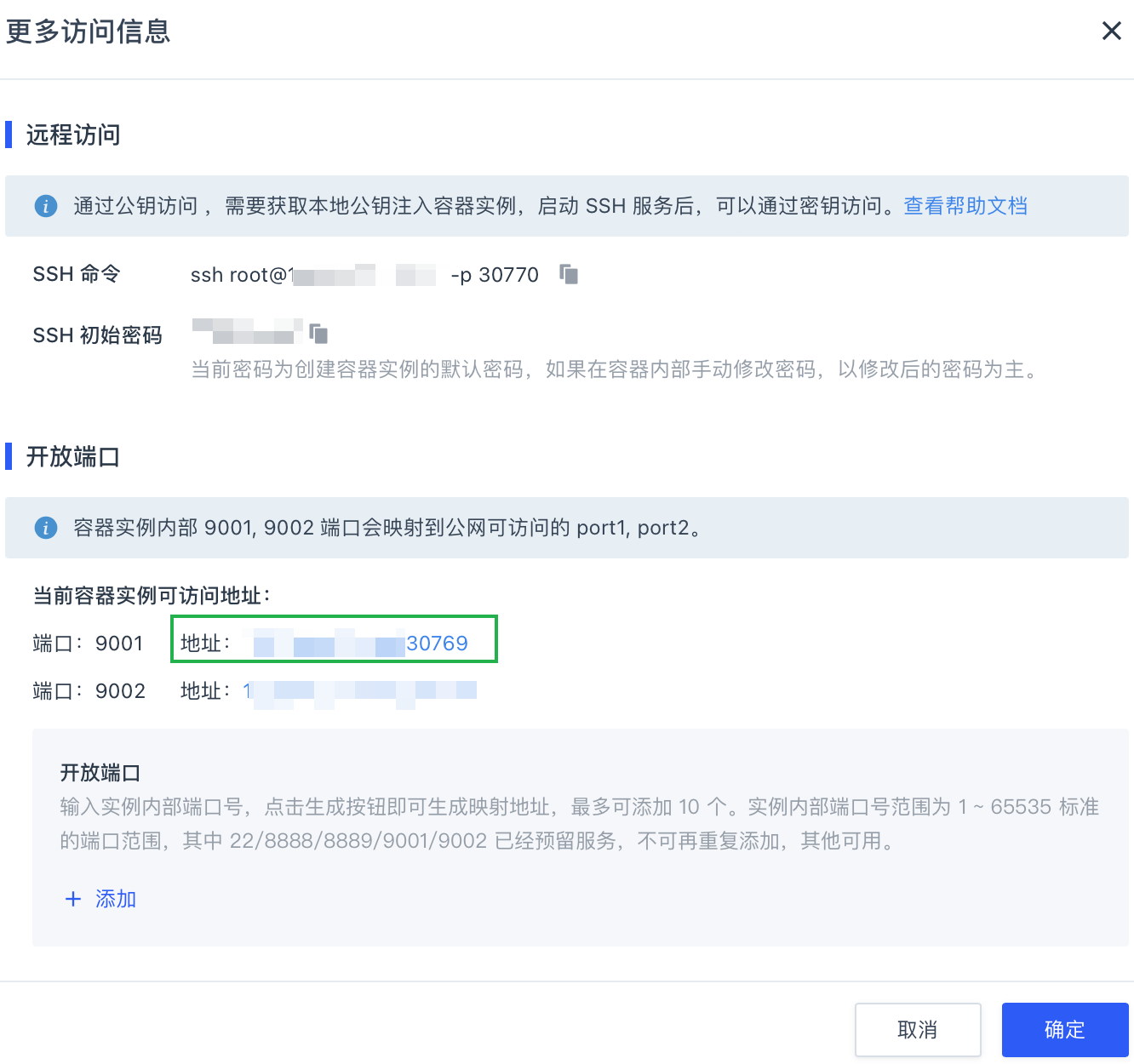
-
进入模型应用界面,根据界面提示选择推理模式,按照相应操作步骤提示,生成指定音频。
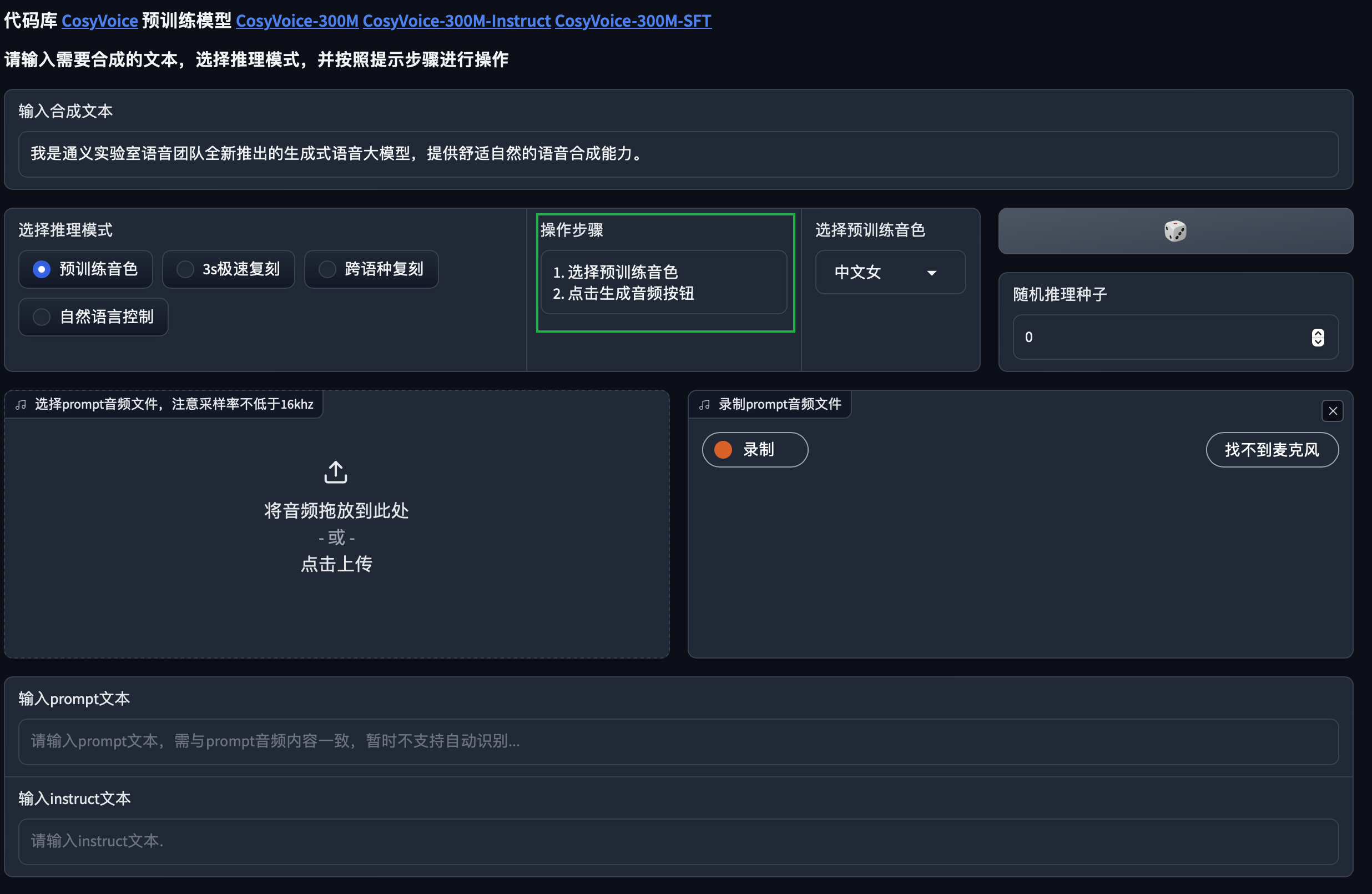
功能说明:
-
预训练音色:使用模型本身预训练音色,按照输入文本生成音频。
-
3s 极速复刻:上传用户自己的音频文件或在线录制音频,模型会根据用户的音频训练出相同音色,输入
prompt文本,就可以使用用户的音色读出来相应的文字。 -
跨语种复刻:将你上传的普通话音频,转变成粤语、日语、英语等。
-
自然语言控制:可在语音中添加自然的笑声,喘气声等语气。使用该功能时,需选择 FunAudioLLM 中的
CosyVoice-300-instruc镜像。
-