创建模型调优任务
模型调优是基于预训练模型,用少量任务数据进行训练,使其更精准地解决用户的特定问题或遵循用户指令,其能显著提升模型在目标场景下的性能。
前提条件
-
已经获取控制台账户和密码。
-
已完成个人实名认证且账户余额大于 0 元。
操作步骤
-
登录控制台,默认进入 AI 计算平台。
-
在左侧导航栏,选择模型调优,默认进入任务列表页面。
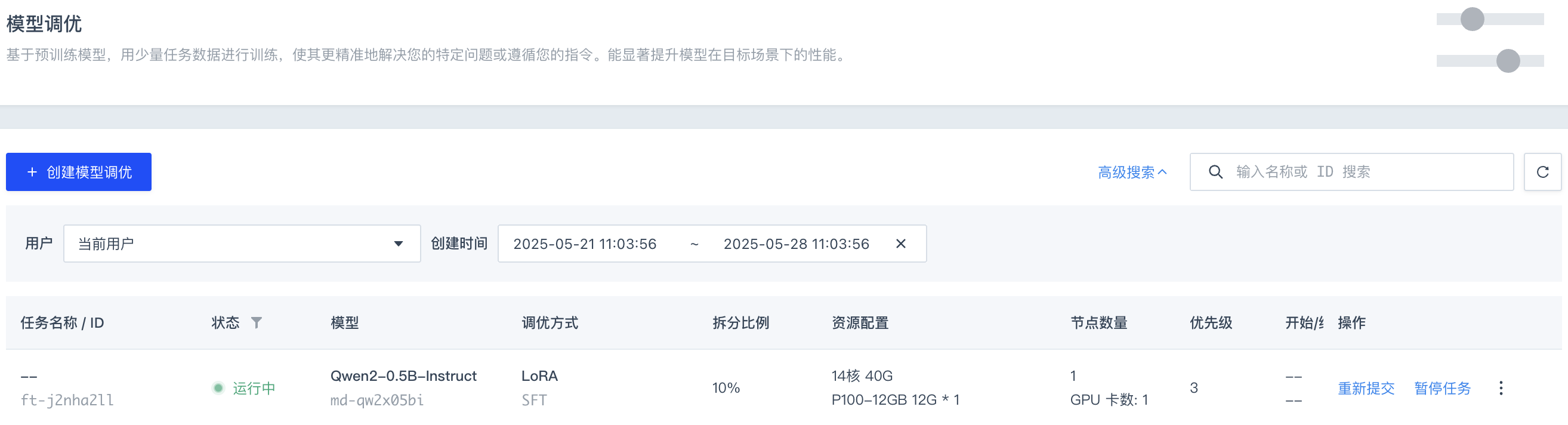
-
点击+ 创建模型调优,在弹出的页面中,根据以下说明配置各项参数,点击确定。
类型 参数 说明 基本信息
任务名称
用户自定义名称,仅支持中文、英文字母、下划线、中划线、数字,长度不超过 50 个。
模型调优方式
目前支持
SFT,即用标注数据训练预训练模型,使其更精准地完成特定任务或遵循指令。基础模型
待调优的模型,支持选择
模型广场或自定义模型。-
模型广场:即平台提前预置的模型文件,用户可自由选择。
-
自定义模型:用户需提前将自有模型添加至平台,具体操作可参考添加模型相关内容。
参数配置
调优方式
目前支持选择
LoRA或Full Fine-Tuning。-
LoRA(Low-Rank Decomposition):在训练中模型主体不变,只微调少量参数,快速适应特定需求。适合大模型的调优,如 LLM 等。
-
Full Fine-Tuning:在训练中调整模型的所有参数,更好适应复杂任务。所需数据量大,任务复杂,适合中小规模的模型,如医学影像诊断等。
参数配置
用户可根据实际需要修改以下参数值:
-
循环次数:即
n_epochs,其代表模型训练过程中模型学习数据集的次数,可理解为看几遍数据,一般建议的范围是1~3遍即可,可依据需求进行调整。推荐范围:[1, 200] -
学习率:即
learning_rate,其代表每次更新数据的增量参数权重,学习率数值越大参数变化越大,对模型影响越大。 -
批次大小:即
batch_size,其代表模型训练过程中,模型更新模型参数的数据步长,可理解为模型每看多少数据即更新一次模型参数。 -
学习率调整策略:即
lr_scheduler_type,选择不同的学习率策略,动态地改变模型在训练过程中更新权重时所采用的学习率大小。 -
验证步数:即
eval_steps,训练阶段针模型的验证间隔步长,用于阶段性评估模型训练准确率、训练损失。推荐范围:[1, 2147483647]。 -
序列长度:即
max_length,训练数据的序列长度,单个训练数据样本的最大长度,超出配置长度将自动截断。推荐范围:[500, 131072]。 -
学习率预热比例:即
warmup_ratio,warmup 占用总的训练 steps 的比例。推荐范围:(0, 1)。 -
模型断点保存间隔:选填,即
save_steps,指训练过程中每隔多少 epoch 或 step 保存一次模型的完整状态(包括模型权重、优化器状态、训练进度等)。 -
梯度积累步数:选填,即
gradient_accumulation_steps,指在 GPU 显存不足时,通过 多次前向传播和反向传播累积梯度,直到累积步数达到设定值后再统一更新模型参数。 -
是否使用 bf16 格式:选填,指是否选择用 16位脑浮点数(bfloat16)作为模型训练或推理的数值精度,用户可根据实际需要进行勾选。
数据配置
调优数据
用于调整训练模型参数以适应特定任务的数据集。用户需提前将所需数据集文件,上传至平台的存储与数据服务的用户目录中,点击
 标识,选择数据集文件。
标识,选择数据集文件。目前仅支持 JSON 格式,且仅允许选择单个文件或文件夹。
验证数据
目前支持选择数据拆分或自定义验集。
-
数据拆分:用户可直接设置训练数据集中一定百分比的数据作为验证集。
-
自定义验证集:用户需提前上传至平台的存储与数据服务的用户目录中,并在此处选择相应文件。
调优模型导出
用于设置调优后的模型文件存储路径。
用户可直接勾选自动保存到模型管理,则相应模型可直接在模型管理页面进行使用或修改。
资源配置
资源
若选择公共资源池,用户可根据实际情况选择当前平台上已有的资源类型和规格。
若选择我的资源组,需配置以下参数。
-
资源组:平台内已创建完成的,且申请了计算资源的可用资源组。
-
指定节点:根据所选资源组,指定相应计算节点,并设置其 vCPU 核数、内存、系统盘大小、GPU 个数(选填)、数据盘大小(选填)。
-
-
等待任务创建成功且状态为
运行中,待任务状态变为完成。 -
在左侧导航栏选择存储与数据服务,点击创建任务时设定的调优模型导出目录,相应目录下会生成一个名为
调优任务 ID的文件夹,在此文件夹下可获取模型调优结果以及调优后的模型文件。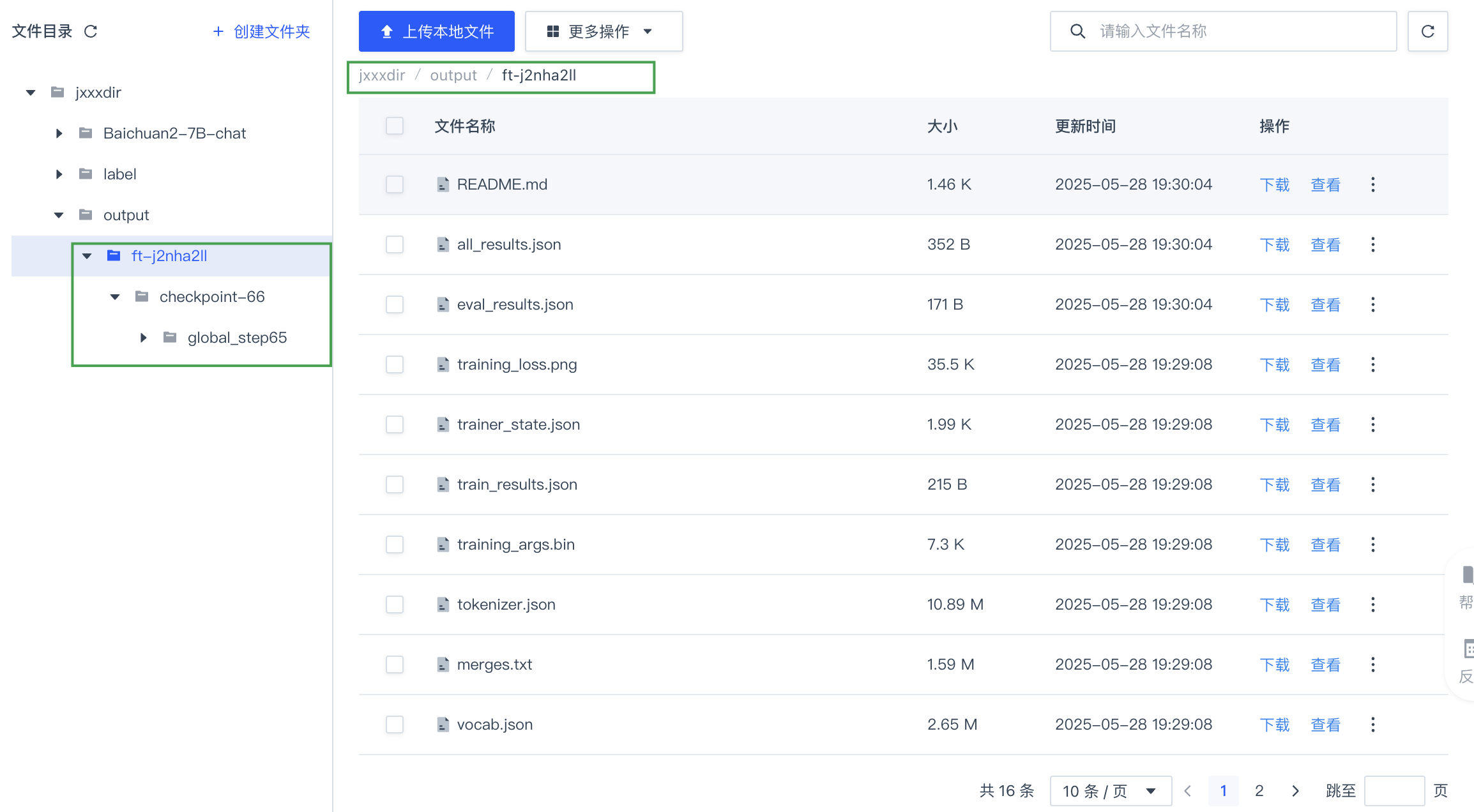
-
若创建任务过程中,在配置调优模型导出参数时,勾选了自动保存到模型管理,则可在左侧导航栏选择模型管理,此时调优完成的模型(名称为
调优任务 ID)已保存在相应列表内,用户可直接用于部署。