在容器实例中使用 vLLM 部署模型
更新时间:2025-06-24 11:00:25
本实践旨在介绍如何使用 vLLM 镜像,在容器实例中部署并调用平台预置的大语言模型。本文以部署 Baichuan2-7B-chat 模型为例。
前提条件
-
已经获取基石智算控制台账户和密码。
-
已完成实名认证且账户余额大于 0 元。
操作步骤
-
创建容器实例,按照如下要求配置参数。
-
资源类型:本实践将部署 Baichuan2-7B-chat 模型,故选择 1 卡 GPU 资源即可,其他模型用户可根据实际情况选择合适资源。 -
镜像:选择基础镜像中的vllm:xb3-dockerhub.coreshub.cn/aicp/public/vllm/vllm-openai:v0.8.5。 -
其他参数:根据实际情况设定即可。
-
-
点击创建,等待容器实例状态为
运行中。 -
在指定实例所在行,点击更多访问 > Web 连接。

-
平台预置的模型文件均在
/root/public目录下。在弹出的 Web 连接窗口中,执行如下命令,查找Baichuan2-7B-chat模型的存储路径。find /root/public -name "Baichuan2-7B-chat" 2>/dev/null说明 若使用其他模型,用户可自行在
/root/public目录下查找相应文件。 -
执行如下命令,启动模型推理,并开启模型推理服务。
python3 -m vllm.entrypoints.openai.api_server \ --model /root/public/baichuan-inc/Baichuan2-7B-chat \ --host 0.0.0.0 \ --port 8080 \ --dtype auto \ --trust-remote-code-
--model用于指定模型所在路径,需根据上一步返回结果进行修改。
-
-
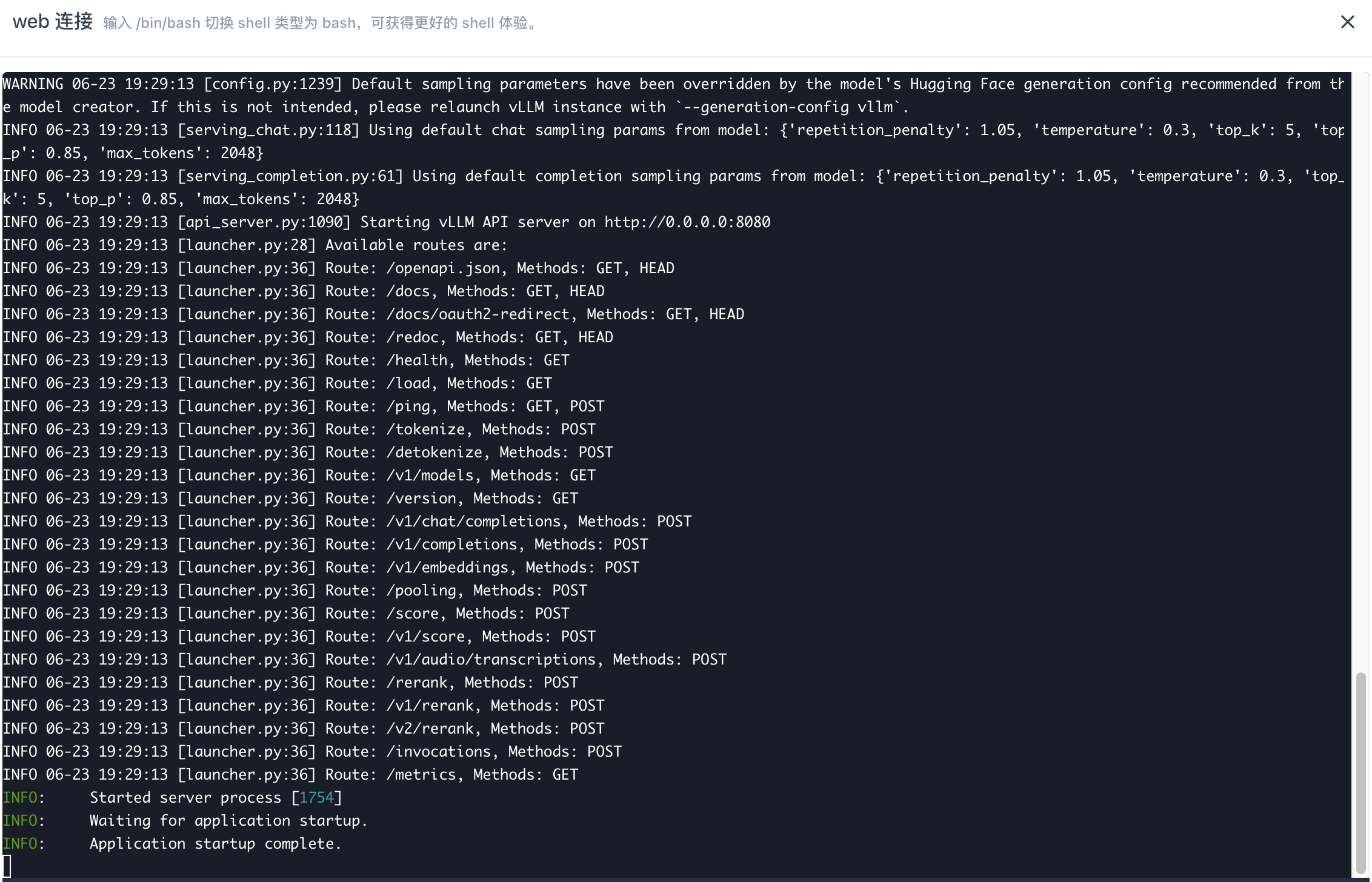
上一步命令回显如下,则说明模型推理服务启动成功。
-
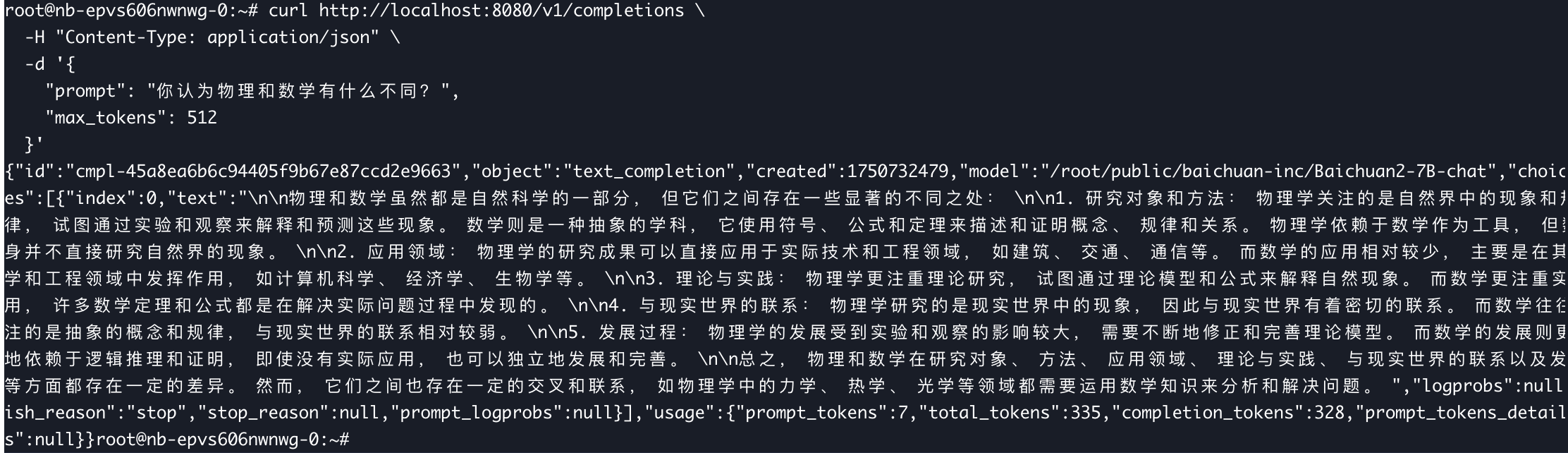
用户可重新开启 Web 连接,执行如下命令,调用模型。
curl http://localhost:8080/v1/completions \ -H "Content-Type: application/json" \ -d '{ "prompt": "你认为物理和数学有什么不同?", "max_tokens": 512 }'