基于 Qwen 模型实现 GRPO
本实践通过复现 DeepSeek-R1 实验,利用智算平台实现 GRPO 算法,提升 Qwen2.5-3B-Instruct 模型的数学计算能力,并借助 SwanLab 监控实验过程,帮助用户深入理解平台使用与 GRPO 实现方法。
背景信息
-
DeepSeek-R1
DeepSeek-R1 以其创新的 GRPO 算法和高效训练能力,为智能模型在复杂数学任务中的表现树立了新的标杆。 DeepSeek-V3 到 DeepSeek-R1 的训练流程如下:
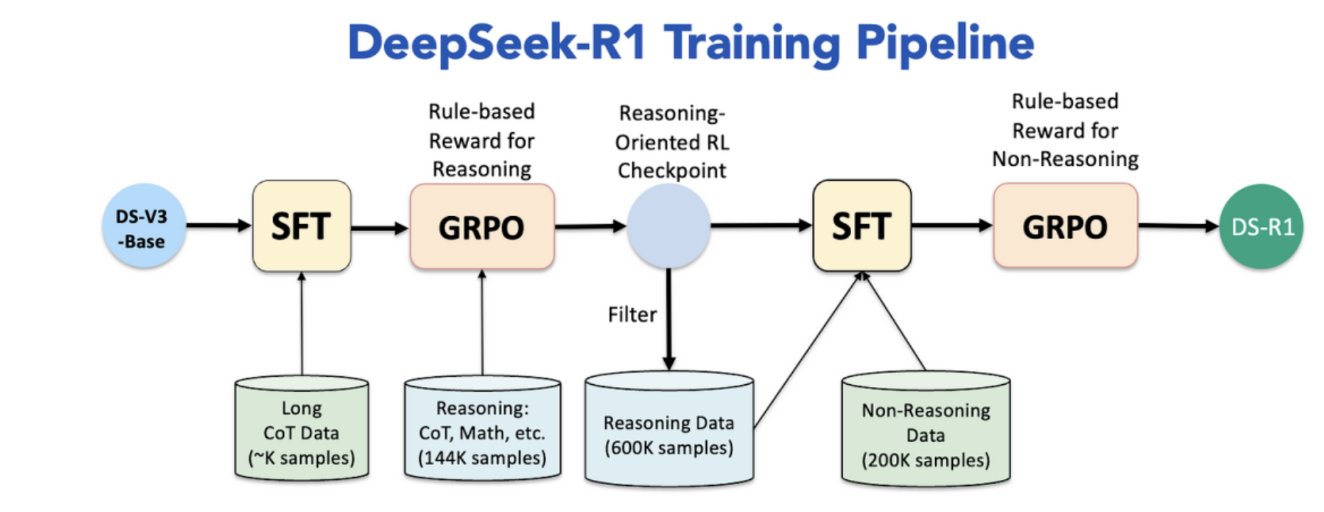
-
第一阶段:冷启动监督微调(Cold Start SFT)
-
第二阶段:面向推理强化学习(Reasoning-Oriented RL)
-
第三阶段:拒绝采样和多领域监督微调(Multi-Domain SFT)
-
第四阶段:全场景强化学习(Final-RL Alignment)
-
-
GRPO 原理
PPO 采用 Actor-Critic 架构,涵盖 Actor(policy)、Critic(Value)、Reward 和 Reference 四种模型。传统的 PPO 使用 Critic 模型来评估模型恢复的总收益,类似比赛中教练指导学员(Actor)的同时也在尝试学习裁判(Reward)的偏好。PPO 的缺陷在于 Actor 与 Critic 的交互会带来过高的成本。
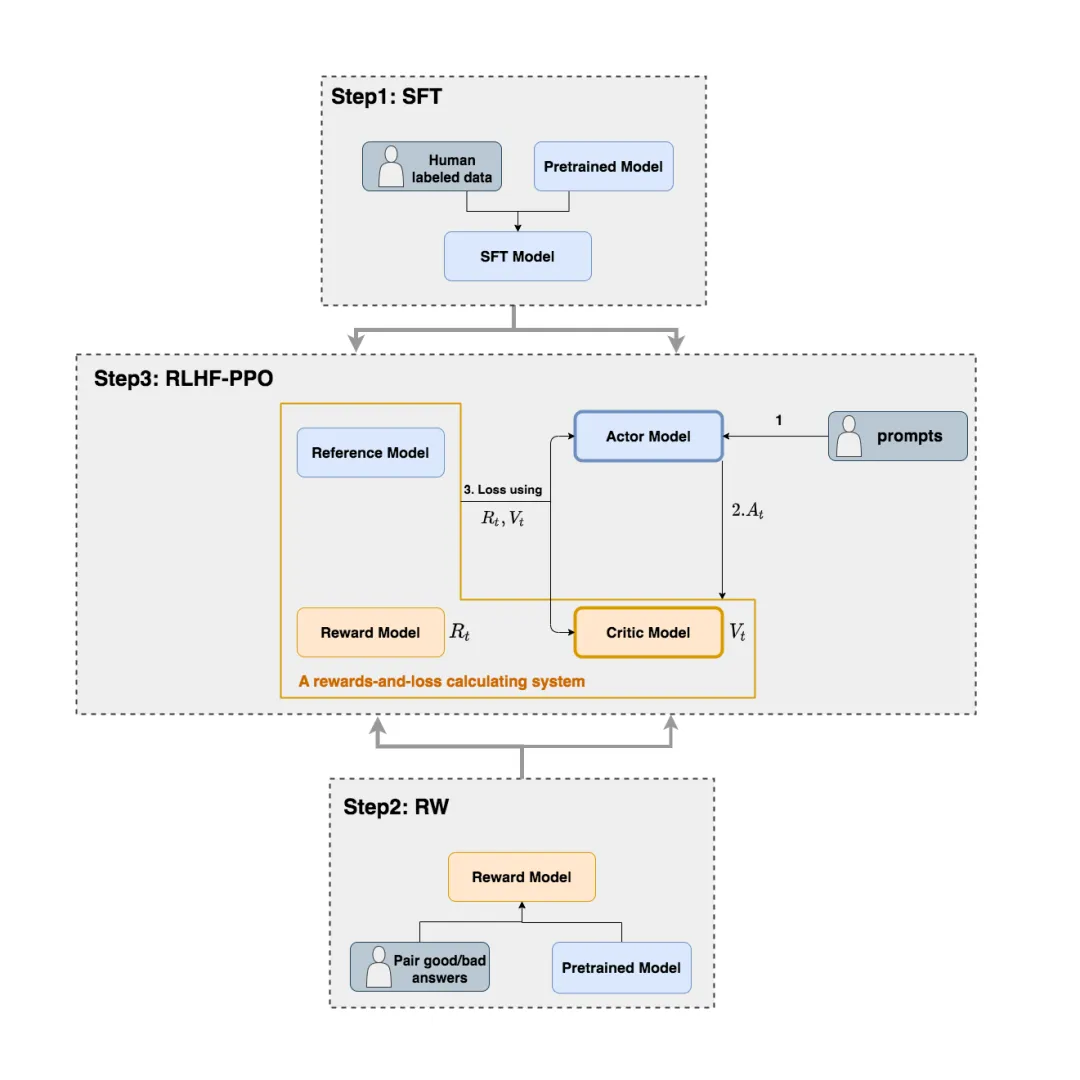
GRPO 的亮点在于去除 Critic 模型,用精心设计的 Rule-based Reward 取代难以调试的 Reward 模型进行判别,最终仅需要 Actor 和 Reference 两个模型,成本更低。
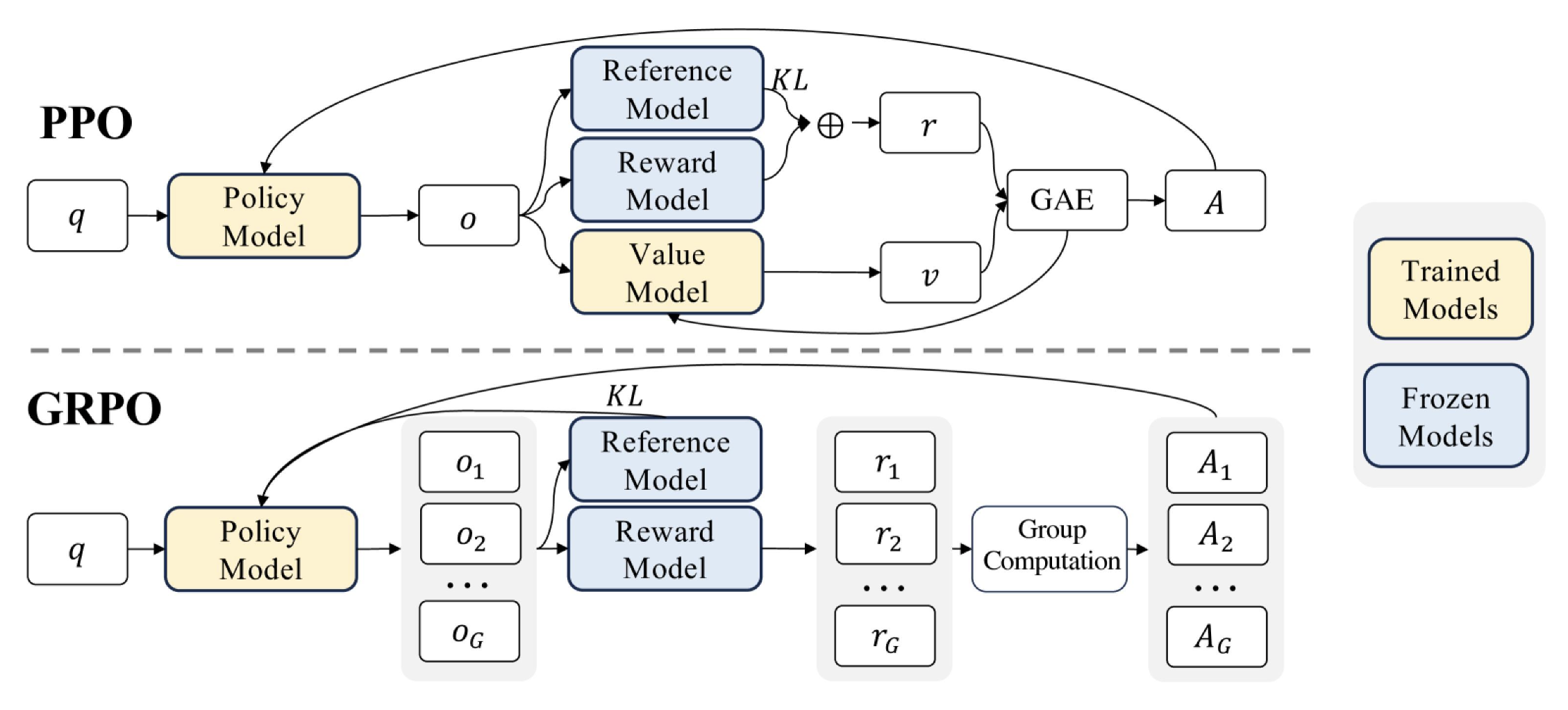
-
SwanLab
SwanLab 工具主要实现模型训练过程的观测以及 GPU 情况监测。基本流程如下:
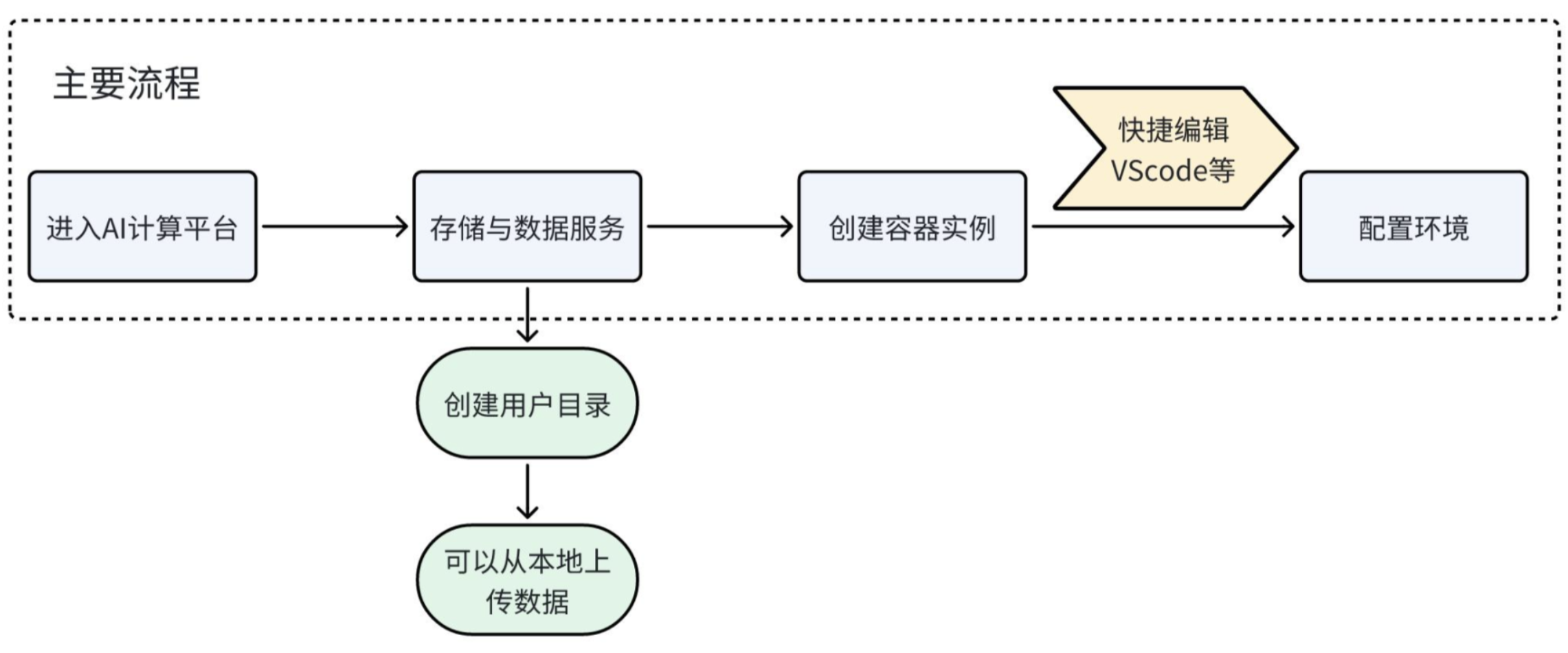
前提条件
-
已经获取基石智算控制台账户和密码。
-
已完成实名认证且账户余额大于 0 元。
-
平台已创建有可用的用户目录,注意,本实践需使用西北三区的 GPU 资源,故需在西北三区创建用户目录。
操作步骤
步骤一:创建容器实例并配置环境
-
进入 AI 计算平台,在顶部导航栏,选择西北三区。
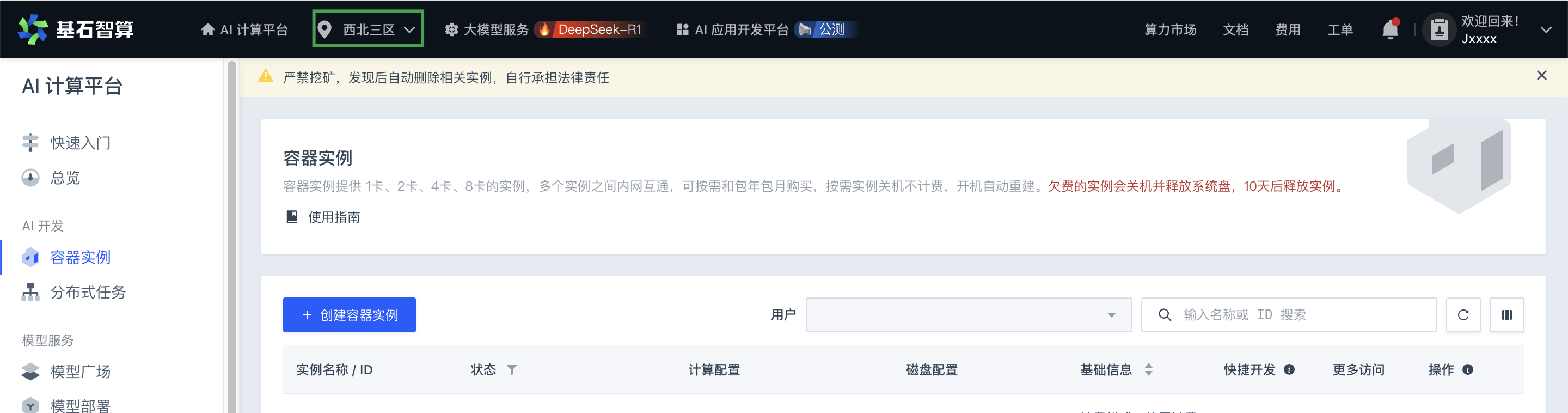
-
在左侧导航栏,选择容器实例,进入实例列表页面。
-
点击创建容器实例,在创建容器实例页面,按如下要求配置各项参数。
-
资源类型:选择西北三区下的NVIDIA-RTX-4090-D 24G * 2的 GPU 资源。 -
存储与数据:选择平台上已存在的用户目录。 -
镜像:选择基础镜像中,Pytorch架构的xb3-dockerhub.coreshub.cn/aicp/public/pytorch:2.5.1-cuda12.4-cudnn-devel。 -
其他参数:保持默认或根据实际情况自定义即可。
-
-
等待容器实例创建完成,且状态为
运行中,点击该容器实例快捷开发列的 jupyter,打开 JupyterLab 页面。
-
在 JupyterLab 页面,选择 Other > Terminal,打开一个新终端。
-
执行如下命令,检查 nvidia 驱动,要求如下图所示。
nvidia-smi
-
执行如下命令,检查 CUDA 驱动,要求如下图所示。
nvcc -V
-
依次执行如下命令,安装相关依赖。
pip install transformers==4.48.1 pip install peft==0.14.0 pip install datasets pip install accelerate pip install trl pip install -U swanlab pip install deepspeed
-
步骤二:准备数据和模型
-
延续上述步骤,在 JupyterLab 的文件浏览区域,双击
epfs文件夹,进入相应目录。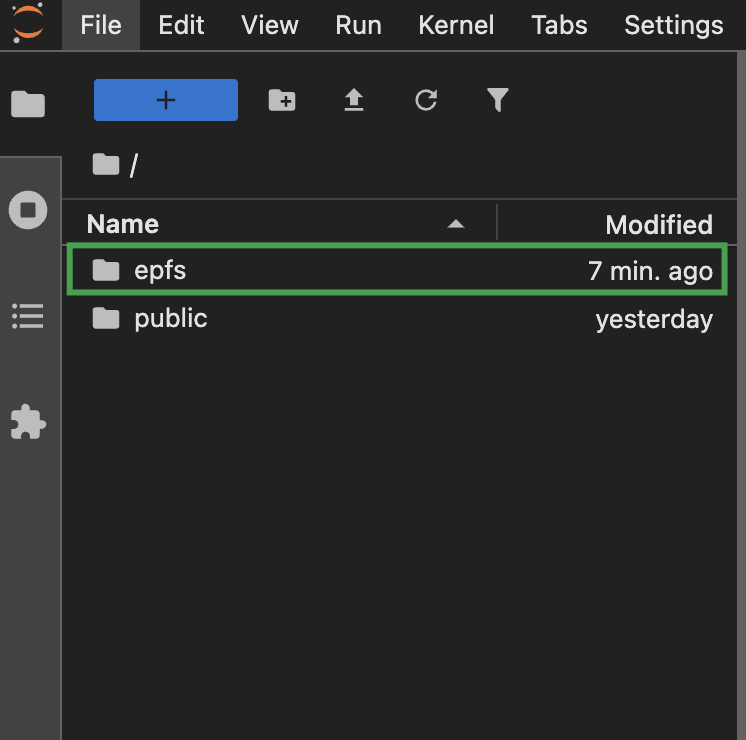
-
在 epfs 目录下,点击鼠标右键,选择 New File,依次创建
train_r1_grpo.py和train_r1_grpo.sh文件,文件内容可参考附录。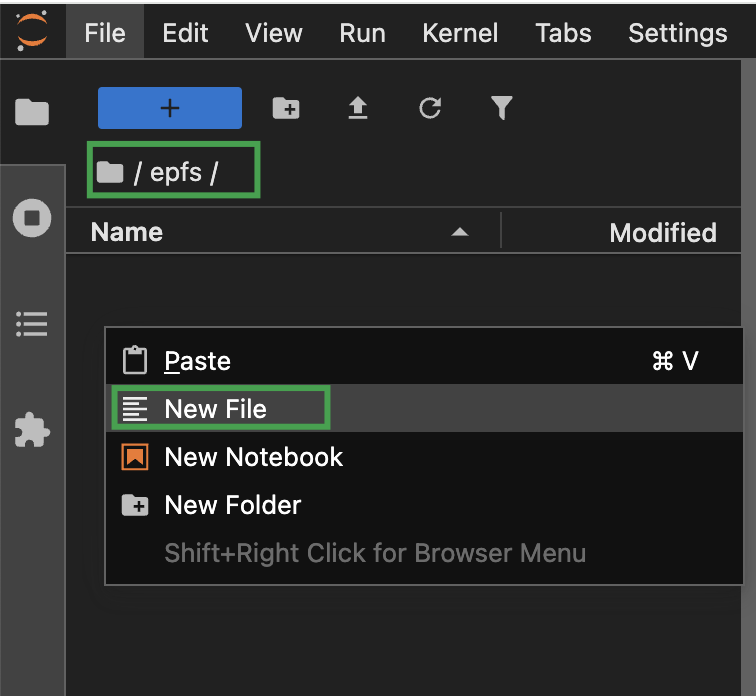
-
在 epfs 目录下,点击鼠标右键,选择 New Folder,依次创建
config、data以及models文件夹。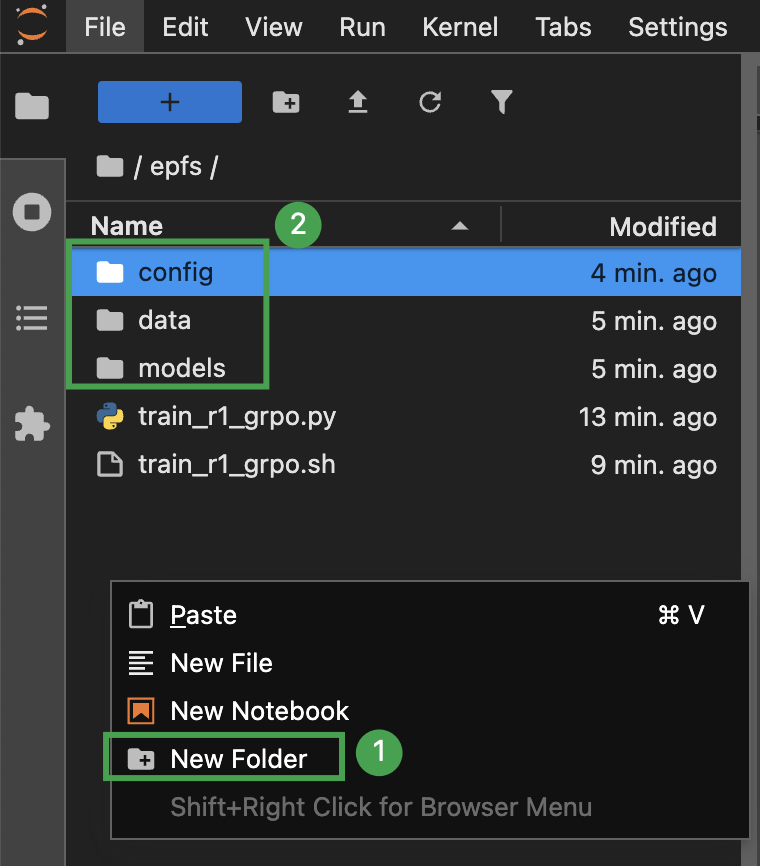
-
双击新建的
config文件夹,点击鼠标右键,选择 New File,依次创建2rtx4090.yaml和grpo-qwen-2.5-3b-deepseek-r1-zero-countdown.yaml文件,用于设置分布式训练以及模型微调参数。文件具体内容可参考附录。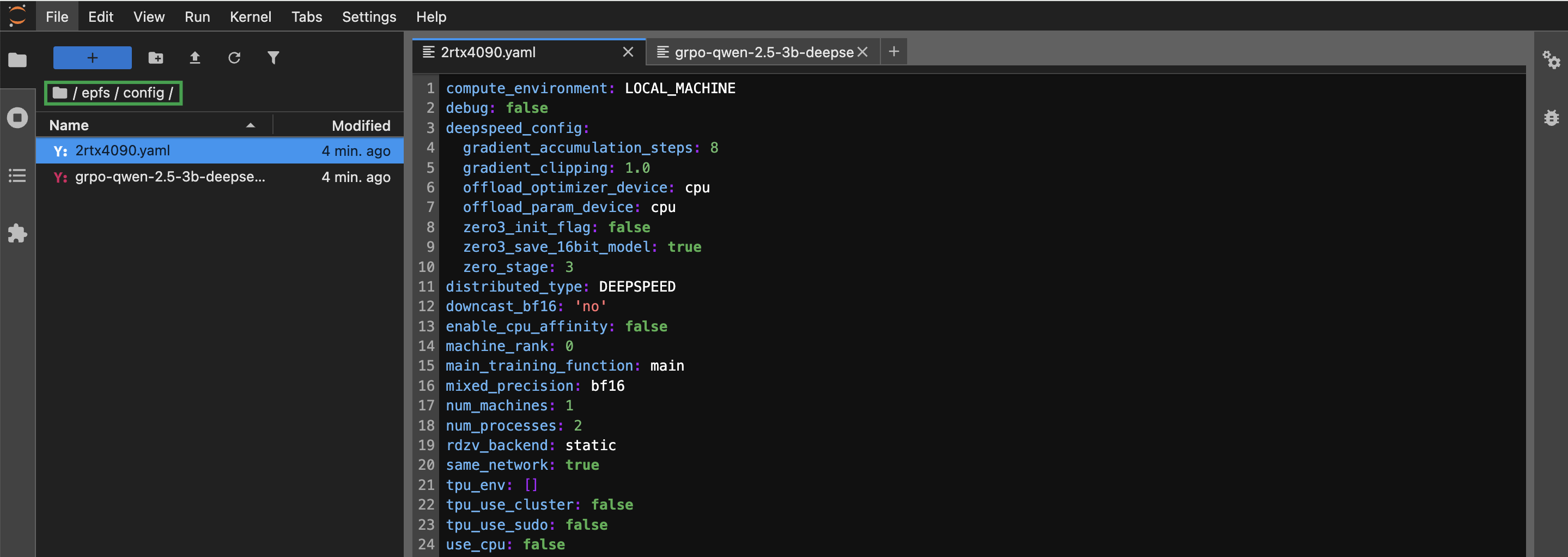
-
返回
epfs目录,双击data文件夹,进入该目录后,点击鼠标右键,选择 New File,创建down_load_data.py文件,用于下载数据集。文件具体内容可参考附录。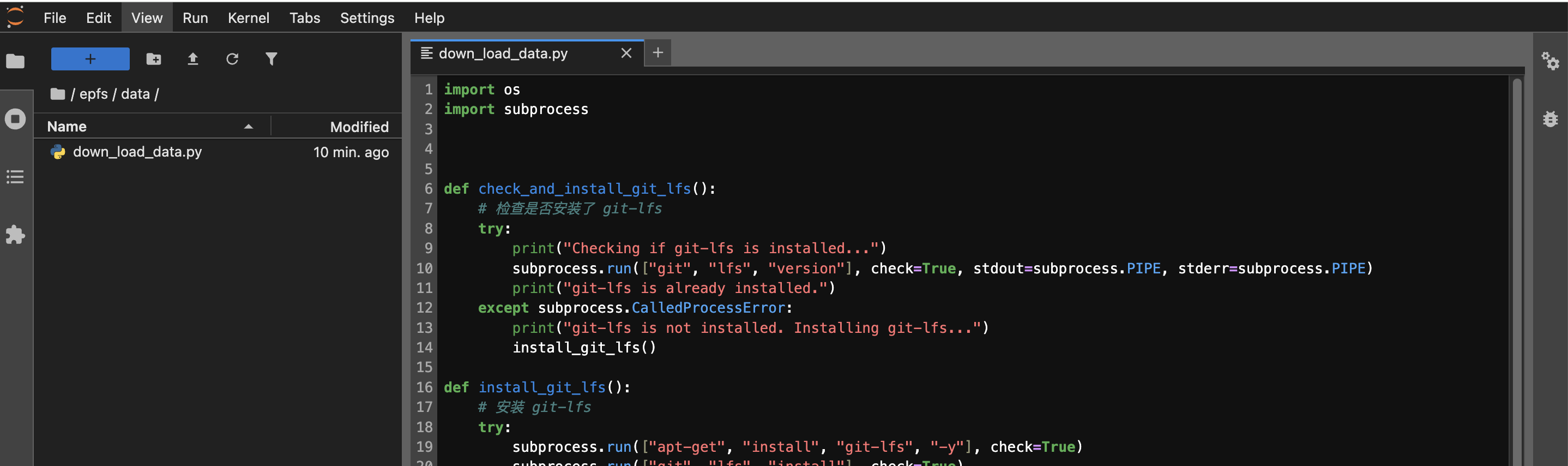
-
返回
epfs目录,双击models文件夹,进入该目录后,点击鼠标右键,选择 New File,创建down_load_model.py文件,用于下载模型。文件具体内容可参考附录。
-
在 JupyterLab 的 Terminal 终端,依次执行如下操作,下载数据集。
-
进入
epfs/data目录。cd epfs/data -
执行 down_load_data.py 文件,下载数据集,数据集下载成功后,可在相应目录下查看到名为
Countdown-Tasks-3to4文件夹。python3 down_load_data.py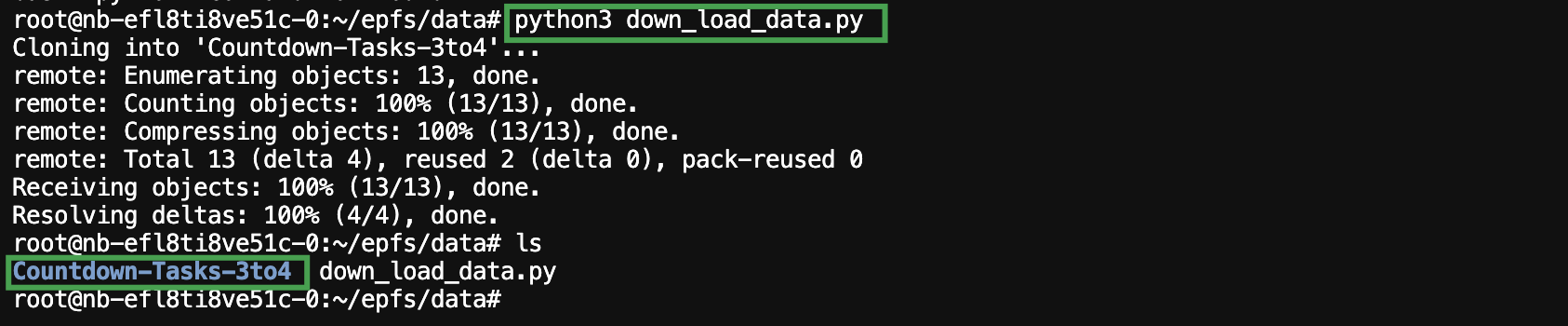
-
-
在 JupyterLab 的 Terminal 终端,执行
cd ~命令,退出epfs/data目录后,依次执行如下操作,下载模型。-
进入
epfs/models目录。cd epfs/models -
执行 down_load_model.py 文件,下载模型,模型下载成功后,可在相应目录下查看到名为
Qwen/Qwen2.5-3B-Instruct的文件夹。注意 模型文件较大可能需要较多时间,请耐心等待。
python3 down_load_data.py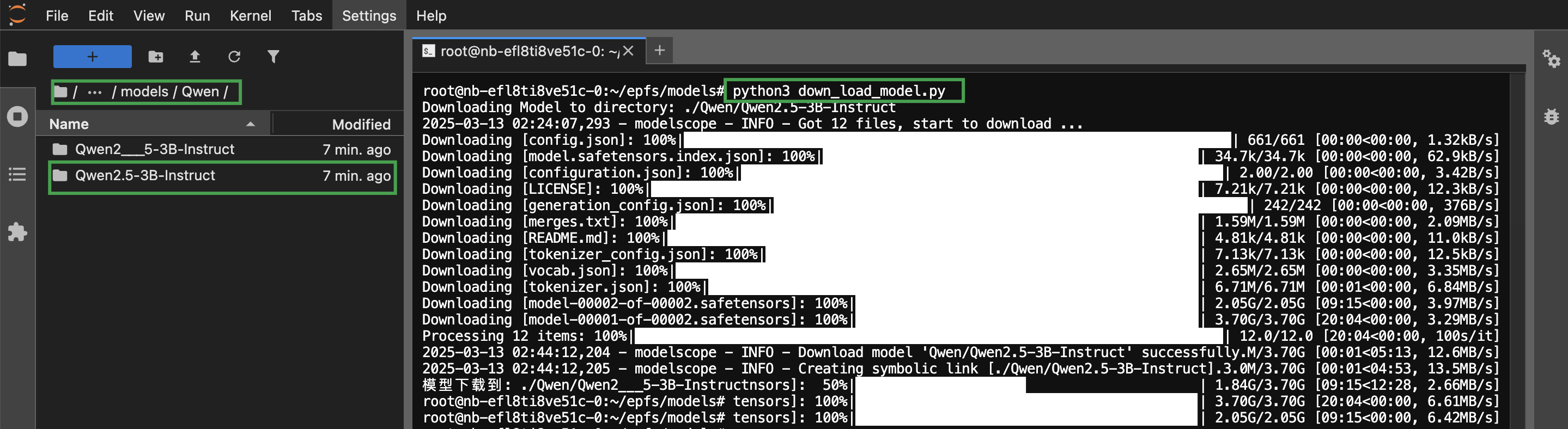
-
步骤三:运行代码
-
延续上述操作,返回
epfs目录。 -
执行如下命令,运行
train_r1_grpo.sh脚本。bash train_r1_grpo.sh -
根据提示,输入相应序号后,获取 SwanLab 的 API 密钥并粘贴在相应位置,点击页面中的相应链接 即可进入 SwanLab。
说明 SwanLab 的 API Key 可点击 https://swanlab.cn/space/~/settings 登录相应账号后,在开发 > API Key 处复制获取。
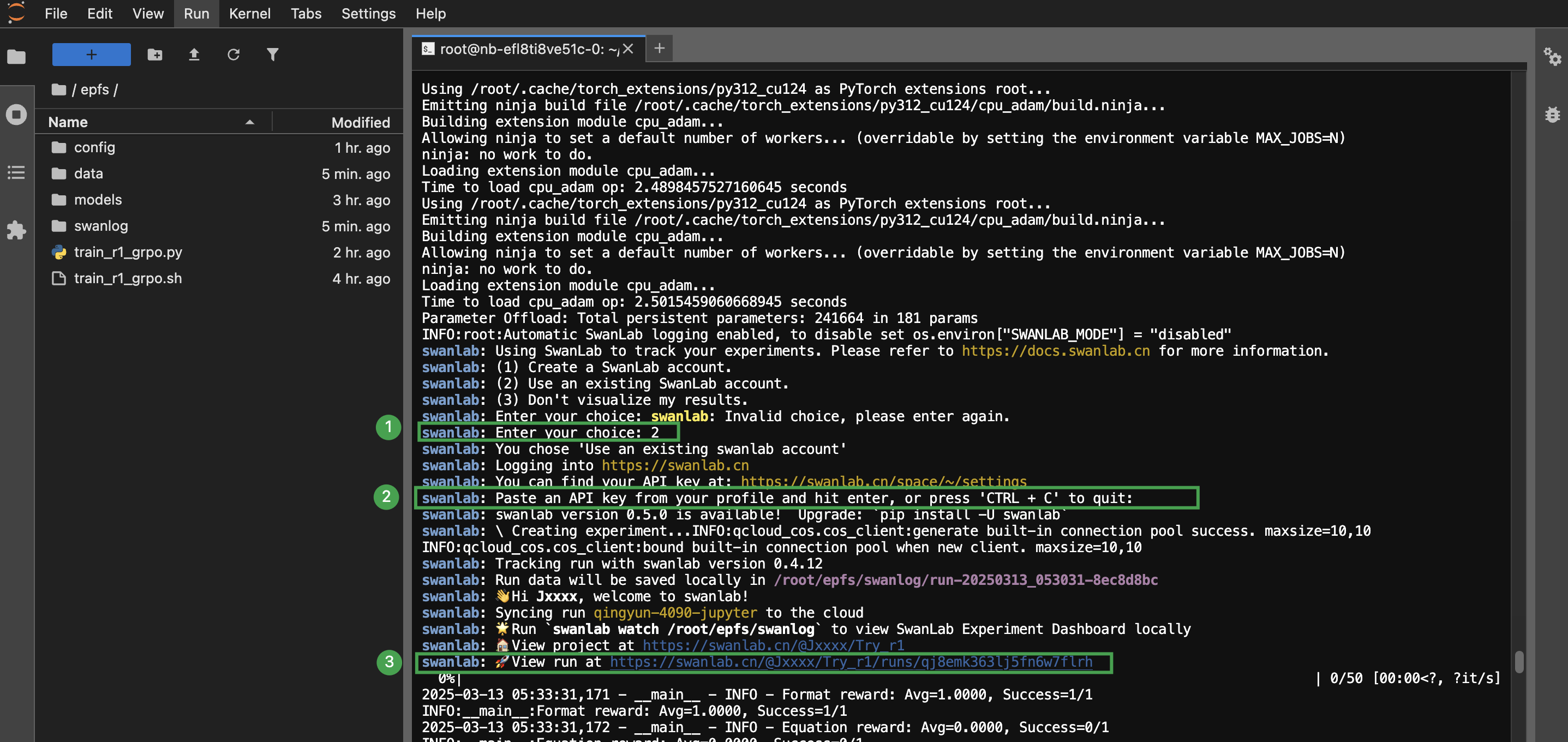
-
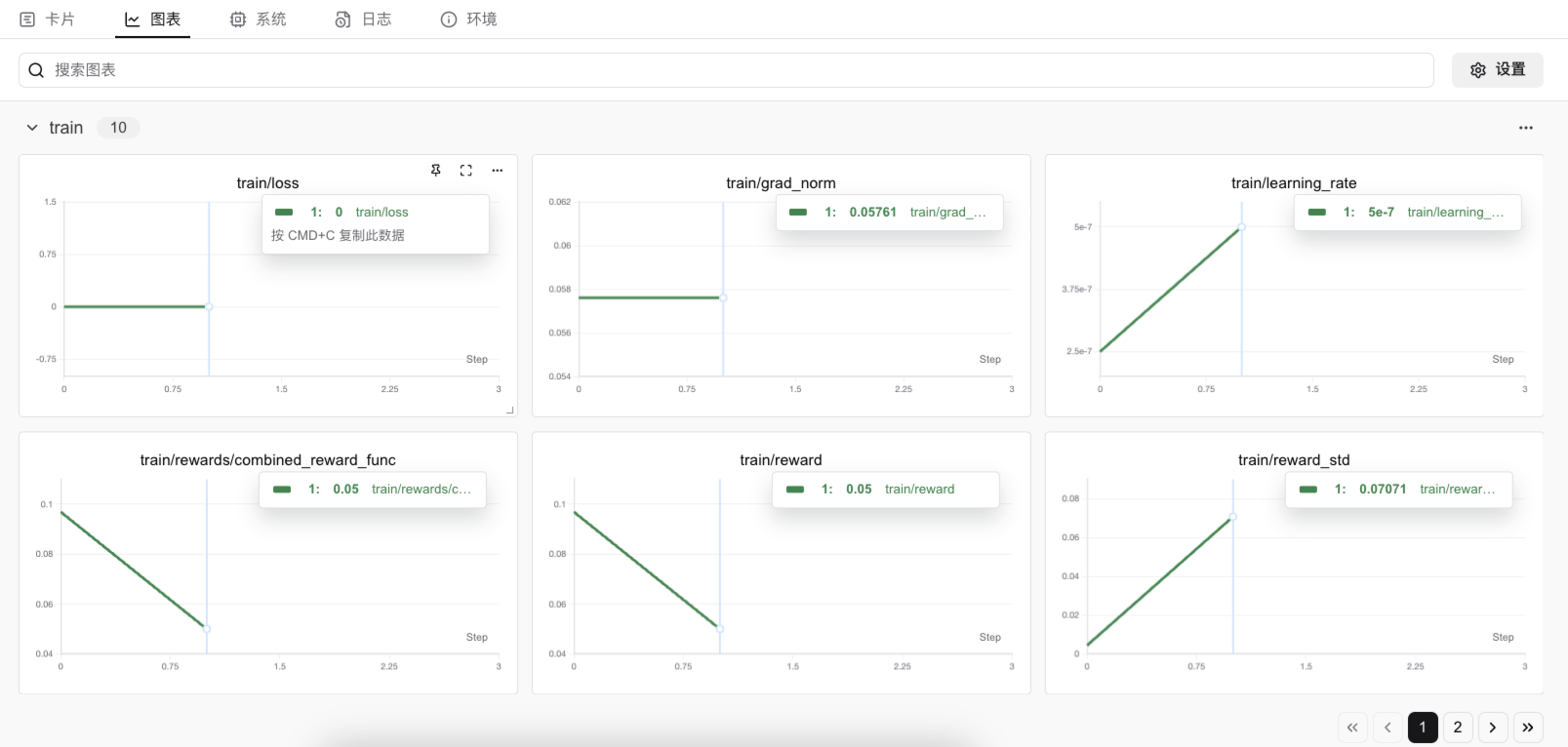
在 SwanLab 的相应实验的图表界面,等待运行一段时间后,即可在观测面板清楚看到模型训练过程。
注意 代码需运行至少 30 分钟后,图表才会有相应的数据显示,请耐心等待。
附录
train_r1_grpo.py
import logging
import os
import random
import re
from dataclasses import dataclass
from datetime import datetime
from typing import List, Dict, Any, Tuple
from datasets import load_dataset
from swanlab.integration.transformers import SwanLabCallback
import torch
from transformers import AutoTokenizer
from transformers.trainer_utils import get_last_checkpoint
from trl import GRPOConfig, GRPOTrainer, ModelConfig, TrlParser
################################################
# 自定义参数类
################################################
@dataclass
class DatasetArguments:
"""数据集参数的数据类"""
# 数据集路径改为本地目录
dataset_id_or_path: str = "./data/Countdown-Tasks-3to4"
# 数据集拆分
dataset_splits: str = "train"
# 分词器名称或路径
tokenizer_name_or_path: str = None
# 添加数据集大小控制
max_train_samples: int = None
# 添加字段,控制标签解析方式
think_answer_required: bool = True
@dataclass
class SwanlabArguments:
"""SwanLab参数的数据类"""
# 是否使用 SwanLab
swanlab: bool = False
# SwanLab 用户名
workspace: str = ""
# SwanLab 的项目名
project: str = ""
# SwanLab 的实验名
experiment_name: str = ""
################################################
# 设置日志记录
################################################
# 配置日志记录器
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
################################################
# 定义奖励函数
################################################
def log_completion_sample(completion, success=False):
"""记录完成样本"""
try:
os.makedirs("completion_samples", exist_ok=True)
log_file = os.path.join(
"completion_samples",
"success_completion_samples.txt" if success else "completion_samples.txt"
)
with open(log_file, "a") as f:
f.write(f"\n\n==============\n")
f.write(f"时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(completion)
except Exception as e:
logger.warning(f"Failed to log completion sample: {e}")
def format_reward_func(completions, **kwargs):
"""
格式奖励函数,检查模型输出格式是否匹配: <think>...</think><answer>...</answer>
改进: 增加内容质量检查,确保 think 和 answer 部分非空且合理
"""
rewards = []
for i, completion in enumerate(completions):
try:
# 确保有 <think> 标签前缀
if not completion.startswith("<think>"):
completion = "<think>" + completion
# 随机记录一些样本用于调试
if random.random() < 0.1:
log_completion_sample(completion)
# 检查完整格式
regex = r"<think>([\s\S]*?)<\/think>\s*<answer>([\s\S]*?)<\/answer>"
match = re.search(regex, completion, re.DOTALL)
if match is None or len(match.groups()) != 2:
# 尝试宽松匹配
think_part = re.search(r"<think>([\s\S]*?)(?:<\/think>|$)", completion, re.DOTALL)
answer_part = re.search(r"<answer>([\s\S]*?)(?:<\/answer>|$)", completion, re.DOTALL)
if think_part and answer_part:
# 检查内容是否为空
think_content = think_part.group(1).strip()
answer_content = answer_part.group(1).strip()
if think_content and answer_content:
rewards.append(0.5) # 格式部分正确但不完整
logger.debug(f"Sample {i}: Format partially correct, non-empty (0.5)")
else:
rewards.append(0.0) # 格式存在但内容为空
logger.debug(f"Sample {i}: Format exists but content empty (0.0)")
else:
rewards.append(0.0) # 格式完全错误
logger.debug(f"Sample {i}: Format incorrect (0.0)")
else:
# 检查 think 和 answer 部分是否为空
think_content, answer_content = match.groups()
think_content = think_content.strip()
answer_content = answer_content.strip()
if not think_content or not answer_content:
rewards.append(0.5) # 格式正确但内容为空
logger.debug(f"Sample {i}: Format correct but content empty (0.5)")
else:
rewards.append(1.0) # 格式和内容都正确
logger.debug(f"Sample {i}: Format and content correct (1.0)")
except Exception as e:
logger.warning(f"Error in format_reward_func for sample {i}: {e}")
rewards.append(0.0)
# 记录总体奖励情况
if rewards:
logger.info(
f"Format reward: Avg={sum(rewards) / len(rewards):.4f}, Success={sum(1 for r in rewards if r > 0.9)}/{len(rewards)}"
)
return rewards
def equation_reward_func(completions, target, nums, **kwargs):
"""
方程奖励函数,检查计算结果是否正确,数字是否符合使用要求
改进: 提高正确性要求,仅在完全正确时给高分,减少部分奖励的慷慨程度
"""
rewards = []
for i, (completion, gt, numbers) in enumerate(zip(completions, target, nums)):
try:
# 确保有 <think> 标签前缀
if not completion.startswith("<think>"):
completion = "<think>" + completion
# 提取 answer 部分
match = re.search(r"<answer>([\s\S]*?)<\/answer>", completion, re.DOTALL)
if match is None:
match = re.search(r"<answer>([\s\S]*?)(?:<\/answer>|$)", completion, re.DOTALL)
if match is None:
rewards.append(0.0)
logger.debug(f"Sample {i}: No answer tag found (0.0)")
continue
equation = match.group(1).strip()
# 清理方程式,移除额外的空格和可能的干扰字符
equation = re.sub(r'[^\d+\-*/().\s]', '', equation).strip()
# 提取使用的数字
used_numbers = [int(n) for n in re.findall(r"\d+", equation)]
# 检查使用的数字是否完全匹配
if sorted(used_numbers) != sorted(numbers):
rewards.append(0.0) # 数字不完全匹配直接给 0
logger.debug(f"Sample {i}: Wrong numbers used (0.0)")
continue
# 检查方程式是否只包含允许的字符
allowed_pattern = r'^[\d+\-*/().\s]+$'
if not re.match(allowed_pattern, equation):
rewards.append(0.0)
logger.debug(f"Sample {i}: Invalid characters in equation (0.0)")
continue
# 安全地计算方程式结果
try:
equation = re.sub(r'(\d+)\s*/\s*(\d+)', r'\1/\2', equation)
result = eval(equation, {"__builtins__": None}, {})
# 计算结果与目标的相对误差
relative_error = abs(float(result) - float(gt)) / (abs(float(gt)) + 1e-10)
if relative_error < 1e-5:
rewards.append(1.0) # 完全正确
if random.random() < 0.1:
log_completion_sample(completion, success=True)
logger.debug(f"Sample {i}: Correct result (1.0)")
elif relative_error < 0.01:
rewards.append(0.5) # 非常接近
logger.debug(f"Sample {i}: Very close result (0.5)")
elif relative_error < 0.1:
rewards.append(0.2) # 较接近
logger.debug(f"Sample {i}: Approximate result (0.2)")
else:
rewards.append(0.0) # 完全错误
logger.debug(f"Sample {i}: Wrong result (0.0)")
except Exception as e:
logger.warning(f"Evaluation error for equation '{equation}': {e}")
rewards.append(0.0)
except Exception as e:
logger.warning(f"Error in equation_reward_func for sample {i}: {e}")
rewards.append(0.0)
# 记录总体奖励情况
if rewards:
logger.info(
f"Equation reward: Avg={sum(rewards) / len(rewards):.4f}, Success={sum(1 for r in rewards if r > 0.9)}/{len(rewards)}"
)
return rewards
def combined_reward_func(completions, **kwargs):
"""
组合奖励函数,结合格式和方程正确性
"""
format_rewards = format_reward_func(completions, **kwargs)
equation_rewards = equation_reward_func(completions, **kwargs)
# 加权平均组合奖励 (格式占10%,方程正确性占90%)
combined_rewards = [0.1 * fr + 0.9 * er for fr, er in zip(format_rewards, equation_rewards)]
if combined_rewards:
logger.info(f"Combined reward: Avg={sum(combined_rewards) / len(combined_rewards):.4f}")
return combined_rewards
################################################
# 数据处理函数
################################################
def preprocess_dataset(dataset, tokenizer, max_samples=None, seed=42):
"""
预处理数据集
"""
if max_samples is not None and max_samples < len(dataset):
dataset = dataset.shuffle(seed=seed).select(range(max_samples))
train_test_split = dataset.train_test_split(test_size=0.1, seed=seed)
train_dataset = train_test_split["train"]
test_dataset = train_test_split["test"]
logger.info(f"Train dataset size: {len(train_dataset)}")
logger.info(f"Test dataset size: {len(test_dataset)}")
return train_dataset, test_dataset
def generate_r1_prompt(numbers, target, tokenizer):
"""
生成 R1 Countdown 游戏提示词
改进: 更清晰的指令,更好的格式要求
"""
r1_prefix = [
{
"role": "user",
"content": (
f"使用给定的数字 {numbers},创建一个等于 {target} 的方程。"
f"你可以使用基本算术运算(+、-、*、/)一次或多次,但每个数字只能使用一次。"
f"在 <think> </think> 标签中展示你的思考过程,"
f"并在 <answer> </answer> 标签中返回最终方程,格式示例: <answer>(1 + 2) / 3</answer>。"
f"<answer>标签中只包含最终的方程式,不要有其他内容。"
f"请确保正确使用标签,并逐步思考如何解决这个问题。"
),
},
{
"role": "assistant",
"content": "让我来思考这个问题。\n<think>",
},
]
return {
"prompt": tokenizer.apply_chat_template(
r1_prefix, tokenize=False, continue_final_message=True
),
"target": target,
"nums": numbers,
}
################################################
# 断点续训处理
################################################
def get_checkpoint(training_args: GRPOConfig):
"""
获取最后一个检查点
"""
last_checkpoint = None
if os.path.isdir(training_args.output_dir):
last_checkpoint = get_last_checkpoint(training_args.output_dir)
return last_checkpoint
################################################
# 基于trl实现GRPO训练过程
################################################
def grpo_function(
model_args: ModelConfig,
dataset_args: DatasetArguments,
training_args: GRPOConfig,
callbacks: List = None,
):
logger.info(f"Model parameters {model_args}")
logger.info(f"Training/evaluation parameters {training_args}")
################################################
# 处理数据
################################################
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(
(
dataset_args.tokenizer_name_or_path
if dataset_args.tokenizer_name_or_path
else model_args.model_name_or_path
),
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 加载数据集(从本地 Parquet 文件加载)
dataset_path = os.path.join(dataset_args.dataset_id_or_path, "train-00000-of-00001.parquet")
logger.info(f"Loading dataset from parquet file: {dataset_path}")
dataset = load_dataset("parquet", data_files={"train": dataset_path})["train"].select(range(10))
# 应用数据集预处理和提示词生成
dataset = dataset.map(lambda x: generate_r1_prompt(x["nums"], x["target"], tokenizer))
train_dataset, test_dataset = preprocess_dataset(
dataset,
tokenizer,
max_samples=dataset_args.max_train_samples,
seed=training_args.seed
)
# 初始化模型参数
logger.info("*** Initializing model kwargs ***")
torch_dtype = (
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
)
model_kwargs = dict(
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
attn_implementation=model_args.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
)
training_args.model_init_kwargs = model_kwargs
# 更改训练参数以提高性能
if not hasattr(training_args, 'dpo_beta') or training_args.dpo_beta is None:
training_args.dpo_beta = 0.5 # 设置一个默认值
# 添加更高的权重衰减以防止过拟合
if not hasattr(training_args, 'weight_decay') or training_args.weight_decay is None:
training_args.weight_decay = 0.01
# 确保learning rate合理设置
if not hasattr(training_args, 'learning_rate') or training_args.learning_rate is None:
training_args.learning_rate = 1e-4
################################################
# 设置 GRPOTrainer
################################################
trainer = GRPOTrainer(
model=model_args.model_name_or_path,
reward_funcs=[combined_reward_func], # 使用组合奖励函数
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
callbacks=callbacks,
)
last_checkpoint = get_checkpoint(training_args)
if last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(f"Checkpoint detected, resuming training at {last_checkpoint}.")
logger.info(
f'*** Starting training {datetime.now().strftime("%Y-%m-%d %H:%M:%S")} for {training_args.num_train_epochs} epochs***'
)
################################################
# 训练模型
################################################
train_result = trainer.train(resume_from_checkpoint=last_checkpoint)
################################################
# 保存训练结果
################################################
metrics = train_result.metrics
metrics["train_samples"] = len(train_dataset)
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
logger.info("*** Training complete ***")
logger.info("*** Save model ***")
trainer.model.config.use_cache = True
trainer.save_model(training_args.output_dir)
logger.info(f"Model saved to {training_args.output_dir}")
# 确保分布式训练时等待所有进程完成
if hasattr(training_args, 'distributed_state') and training_args.distributed_state:
training_args.distributed_state.wait_for_everyone()
tokenizer.save_pretrained(training_args.output_dir)
logger.info(f"Tokenizer saved to {training_args.output_dir}")
logger.info("*** Training complete! ***")
def main():
parser = TrlParser((ModelConfig, DatasetArguments, GRPOConfig, SwanlabArguments))
model_args, dataset_args, training_args, swanlab_args = parser.parse_args_and_config()
callbacks = []
if swanlab_args.swanlab:
swanlab_callback = SwanLabCallback(
project=swanlab_args.project,
experiment_name=swanlab_args.experiment_name,
)
callbacks.append(swanlab_callback)
grpo_function(model_args, dataset_args, training_args, callbacks=callbacks)
if __name__ == "__main__":
main()train_r1_grpo.sh
#!/bin/bash
accelerate launch \
--num_processes 2 \
--config_file config/2rtx4090.yaml \
train_r1_grpo.py \
--config config/grpo-qwen-2.5-3b-deepseek-r1-zero-countdown.yaml2rtx4090.yaml
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
gradient_accumulation_steps: 8
gradient_clipping: 1.0
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: false
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
enable_cpu_affinity: false
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: falsegrpo-qwen-2.5-3b-deepseek-r1-zero-countdown.yaml
# Model arguments
model_name_or_path: /root/epfs/models/Qwen/Qwen2.5-3B-Instruct
model_revision: main
torch_dtype: bfloat16
bf16: true
tf32: false
output_dir: /root/project/output
# Dataset arguments
dataset_id_or_path: /root/epfs/data/Countdown-Tasks-3to4
# Training arguments
max_steps: 50
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
gradient_checkpointing: false
gradient_checkpointing_kwargs:
use_reentrant: false
learning_rate: 5.0e-7
lr_scheduler_type: cosine
warmup_ratio: 0.03
# GRPO specific parameters
beta: 0.001
max_prompt_length: 256
max_completion_length: 1024
num_generations: 2
use_vllm: false
vllm_device: "cuda:1"
vllm_gpu_memory_utilization: 0.8
# Logging arguments
logging_strategy: steps
logging_steps: 1
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 2025
# Swanlab 训练流程记录参数
swanlab: true
workspace: none
project: Try_r1
experiment_name: qingyun-4090-jupyterdown_load_data.py
import os
import subprocess
def check_and_install_git_lfs():
# 检查是否安装了 git-lfs
try:
print("Checking if git-lfs is installed...")
subprocess.run(["git", "lfs", "version"], check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print("git-lfs is already installed.")
except subprocess.CalledProcessError:
print("git-lfs is not installed. Installing git-lfs...")
install_git_lfs()
def install_git_lfs():
# 安装 git-lfs
try:
subprocess.run(["apt-get", "install", "git-lfs", "-y"], check=True)
subprocess.run(["git", "lfs", "install"], check=True)
print("git-lfs has been installed successfully.")
except subprocess.CalledProcessError as e:
print(f"Error installing git-lfs: {e}")
exit(1)
def clone_repo():
# 克隆 Git 仓库
repo_url = "https://www.modelscope.cn/datasets/zouxuhong/Countdown-Tasks-3to4.git"
clone_command = f"git clone {repo_url}"
try:
print(f"Cloning repository from {repo_url}...")
os.system(clone_command)
print("Repository cloned successfully.")
except Exception as e:
print(f"Error cloning repository: {e}")
def pull_lfs():
# 拉取 Git LFS 文件
try:
print("Pulling large files with Git LFS...")
os.system("git lfs pull")
print("Git LFS pull completed successfully.")
except Exception as e:
print(f"Error pulling Git LFS files: {e}")
def main():
# 检查并安装 git-lfs(如果没有安装)
check_and_install_git_lfs()
# 调用克隆仓库和拉取 LFS 文件的函数
clone_repo()
pull_lfs()
if __name__ == "__main__":
main()down_load_model.py
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-3B-Instruct', cache_dir='./')
print(f"模型下载到: {model_dir}")