基于 PyTorch 的 LLaMA 2 模型微调
更新时间:2024-11-07 06:26:01
LLaMA 是比较常用的开源模型,智算平台的基础镜像中已内置 LLaMA 2 微调所需的模型,此最佳实践介绍如何在基础镜像列表中使用指定镜像文件,一键快速提交分布式训练任务,完成基于 LLaMA 2 7B 的中文预训练模型微调。
前提条件
-
已经获取控制台账户和密码。
-
已完成实名认证且账户余额大于 0 元。
操作步骤
-
登录控制台,默认进入 AI 计算平台。
-
在左侧导航栏,选择分布式任务,进入任务列表页面。
-
点击创建训练任务,在弹出的创建训练任务页面,按如下要求配置各项参数。
-
任务类型:选择 Pre-train。 -
框架:选择 PyTorch。
-
镜像:选择基础镜像,Pytorch,public/llama2-train:pytorch-2.1.2-cuda12.1-cudnn8-with-model。 -
启动命令:直接输入bash main-train.sh即可。若需指定模型输出路径,可使用-o参数,指定相应目录即可,如bash main-train.sh -o /root/epfs/output -
资源组:根据实际情况,选择公共资源池或我的资源组,指定相应资源即可。 -
其他参数保持默认,无需进行配置即可。
-
-
等待分布式训练任务创建完成且在
运行中,可查看其详情。 -
分布式训练
运行中或完成后,在任务列表内,点击该任务操作列的 TensorBoard 查看相应的模型计算图。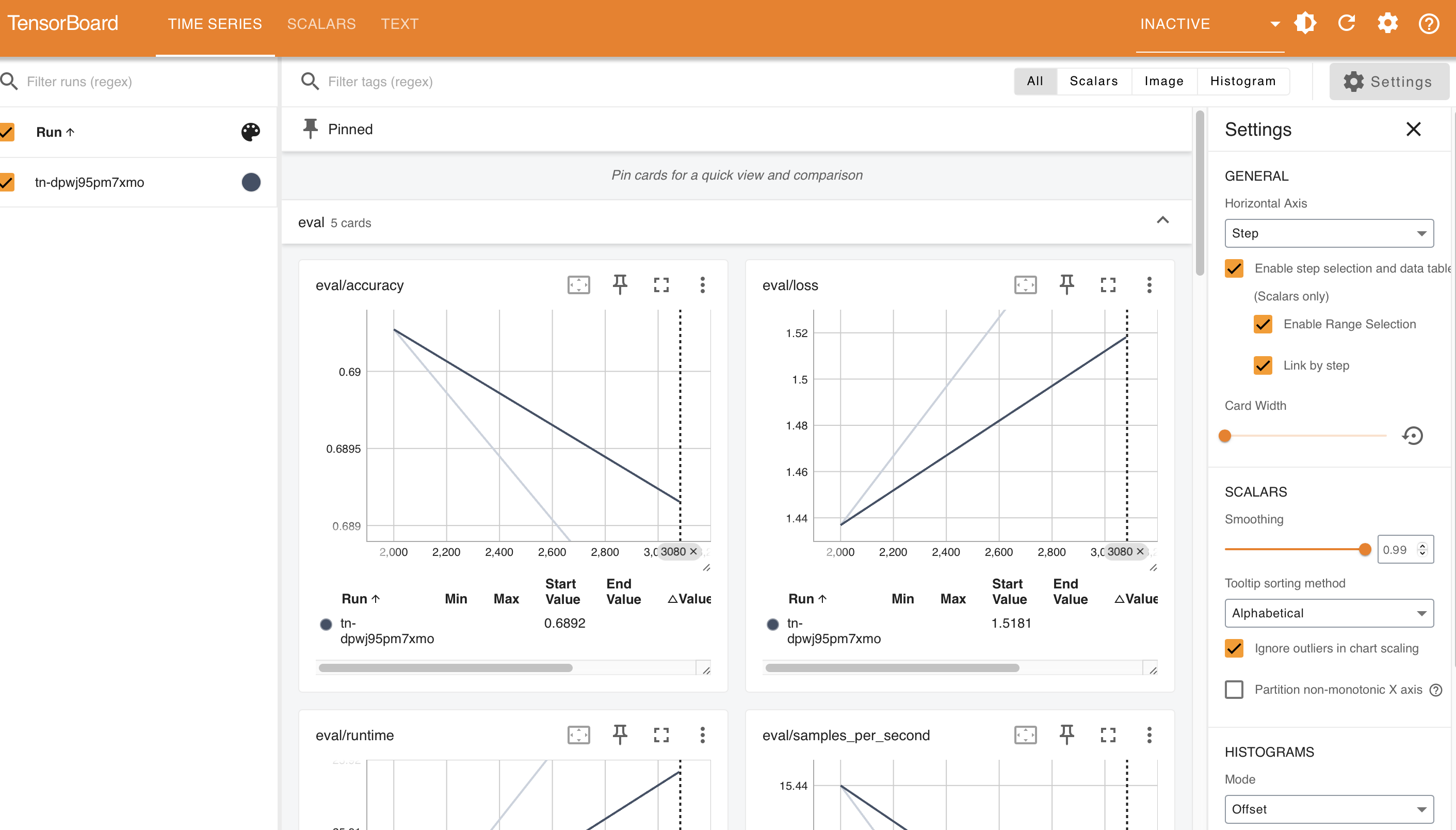
后续操作
附录
本示例训练任务启动命令中使用的启动脚本为 main-train.sh,其内容如下:
#!/bin/bash
default_output_model="/root/Llama-trains/save_folder"
llama_chinese_main_path="/root/Llama-trains/Llama-Chinese/train/sft"
atom_main_path="/root/Llama-trains/Atom-7B-Chat"
cd ${llama_chinese_main_path}
# 解析参数
while getopts "o:" opt; do
case $opt in
o)
output_model=$OPTARG
;;
\?)
echo "Invalid option: -$OPTARG" >&2
exit 1
;;
esac
done
# 如果没有传入参数,使用默认值
if [ -z "$output_model" ]; then
output_model=$default_output_model
fi
# 需要修改到自己的输入目录
if [ ! -d ${output_model} ];then
mkdir ${output_model}
fi
export CUDA_HOME=/usr/local/cuda/
# export NCCL_P2P_DISABLE=1
# export NCCL_IB_DISABLE=1
# export CUDA_VISIBLE_DEVICES=4
ulimit -l unlimited
cd ${llama_chinese_main_path}
torchrun --rdzv-conf read_timeout=900,join_timeout=900 finetune_clm_lora.py \
--model_name_or_path ${atom_main_path} \
--train_files ../../data/train_sft.csv \
--validation_files ../../data/dev_sft.csv \
../../data/dev_sft_sharegpt.csv \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--do_train \
--do_eval \
--use_fast_tokenizer false \
--output_dir ${output_model} \
--evaluation_strategy steps \
--max_eval_samples 800 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 8 \
--num_train_epochs 10 \
--warmup_steps 400 \
--load_in_bits 4 \
--lora_r 8 \
--lora_alpha 32 \
--target_modules q_proj,k_proj,v_proj,o_proj,down_proj,gate_proj,up_proj \
--logging_dir ${TENSORBOARD_LOG_PATH} \
--logging_strategy steps \
--logging_steps 10 \
--save_strategy steps \
--preprocessing_num_workers 10 \
--save_steps 2000 \
--eval_steps 2000 \
--save_total_limit 200 \
--seed 42 \
--disable_tqdm false \
--ddp_find_unused_parameters false \
--block_size 2048 \
--report_to tensorboard \
--deepspeed ds_config_zero2.json \
--overwrite_output_dir \
--ignore_data_skip true \
--bf16 \
--gradient_checkpointing \
--bf16_full_eval \
--ddp_timeout 18000000 \
| tee -a ${output_model}/train.log
# --resume_from_checkpoint ${output_model}/checkpoint-20400 \