使用容器实例进行 LLaMA Factory 模型微调
LLaMA Factory 是一款开源低代码大模型微调框架,集成了业界广泛使用的微调技术。本实践旨在介绍如何使用 LLaMA Factory 对 llama3-8b-instruct 模型进行基于 LoRA 的 SFT 指令微调。
前提条件
-
已经获取基石智算控制台账户和密码。
-
已完成实名认证且账户余额大于 0 元。
操作步骤
准备环境
-
登录控制台,进入 AI 计算平台。
-
在左侧导航栏,选择容器实例,进入实例列表页面。
-
点击创建容器实例,在创建容器实例页面,按如下要求配置各项参数。
-
资源类型:选择西北三区的NVIDIA-RTX-4090-D 24G * 1即可。 -
存储与数据:选择平台上已创建的用户目录即可。 -
镜像:选择外部镜像地址,并输入hub.kubesphere.com.cn/aicp/llama-factory:latest,勾选无密码。 -
其他参数:保持默认或根据实际情况自定义即可。
-
-
等待容器实例创建完成,且状态为
运行中。
模型训练
-
延续上述操作。
-
点击该容器实例快捷开发列中的 vscode,打开 VSCode Web UI 开发页面。

-
选中
Root目录,点击 New Folder 图标,新建名为datas的文件夹,用于保存数据集。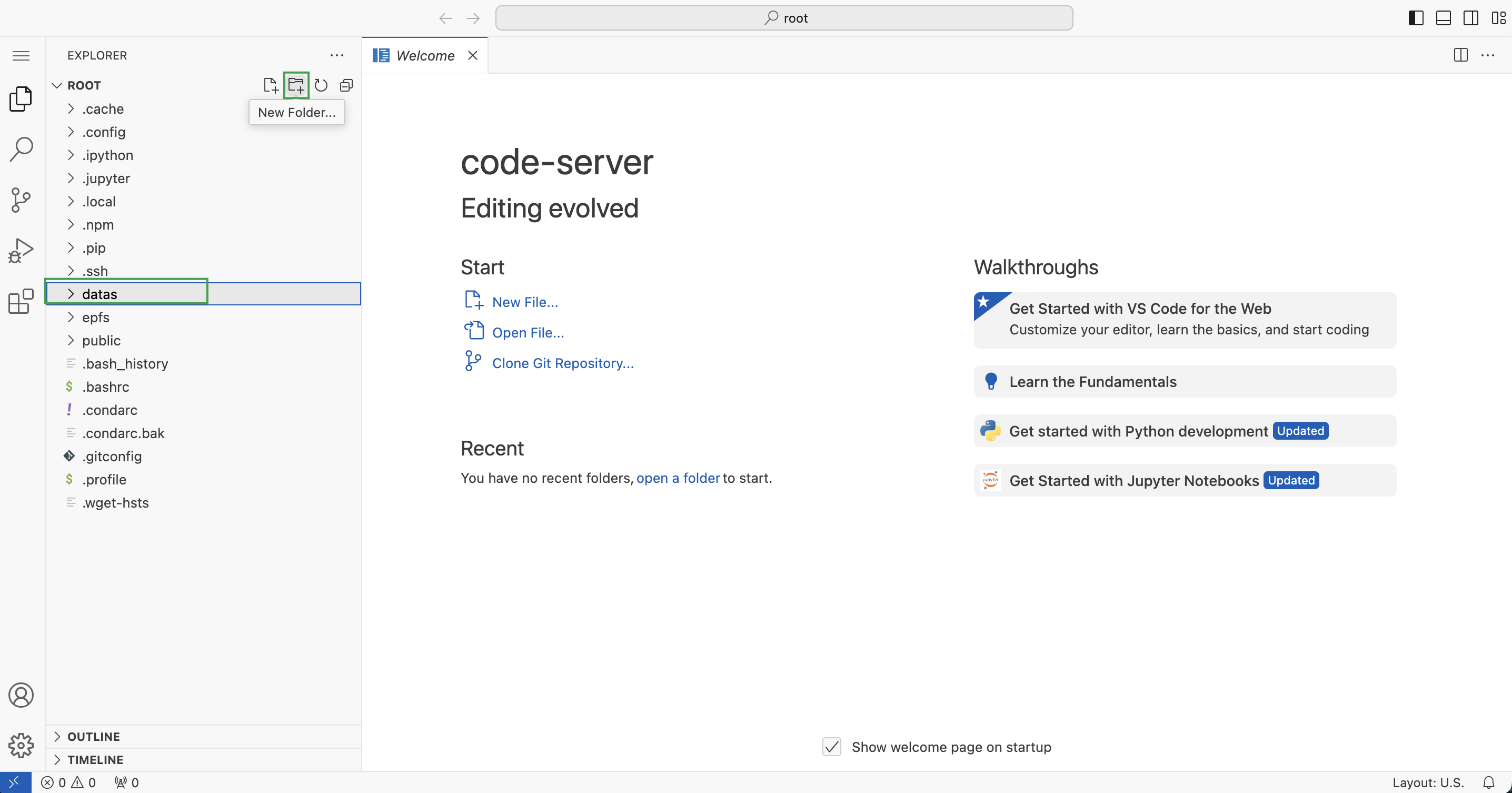
-
打开 vscode 的控制台窗口,依次执行如下命令,下载数据集至
/root/datas目录并进行解压。wget -P /root/datas https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1 tar -xzvf "/root/datas/index.html?dl=1" -C /root/datas/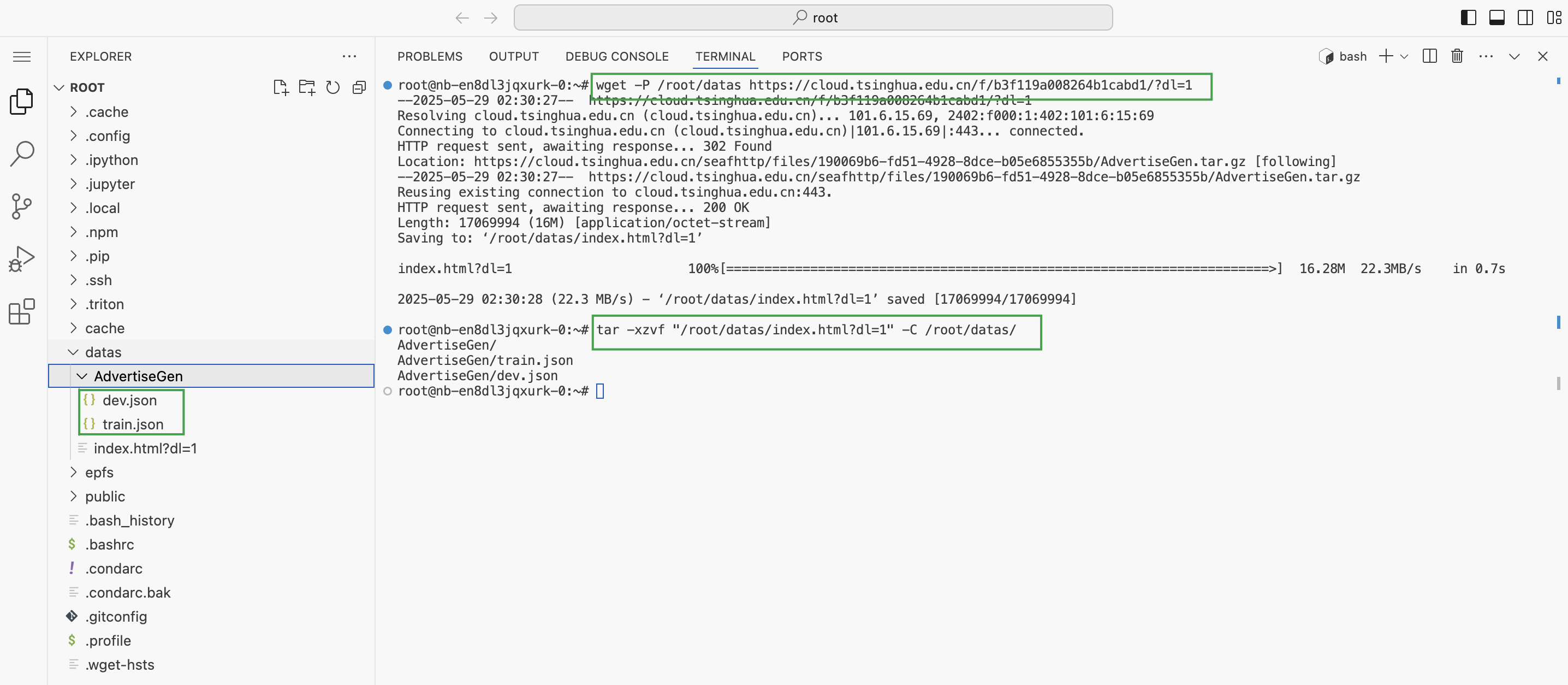
-
上一步下载的数据集文件解压完成后,将其内的
dev.json和train.json文件移动至/root/datas目录。 -
选中
/root/datas目录,点击 New File 图标,新建名为dataset_info.json的文件,文件内容如下。{ "custom_train_data": { "file_name": "train.json", "columns": { "prompt": "content", "response": "summary" } } }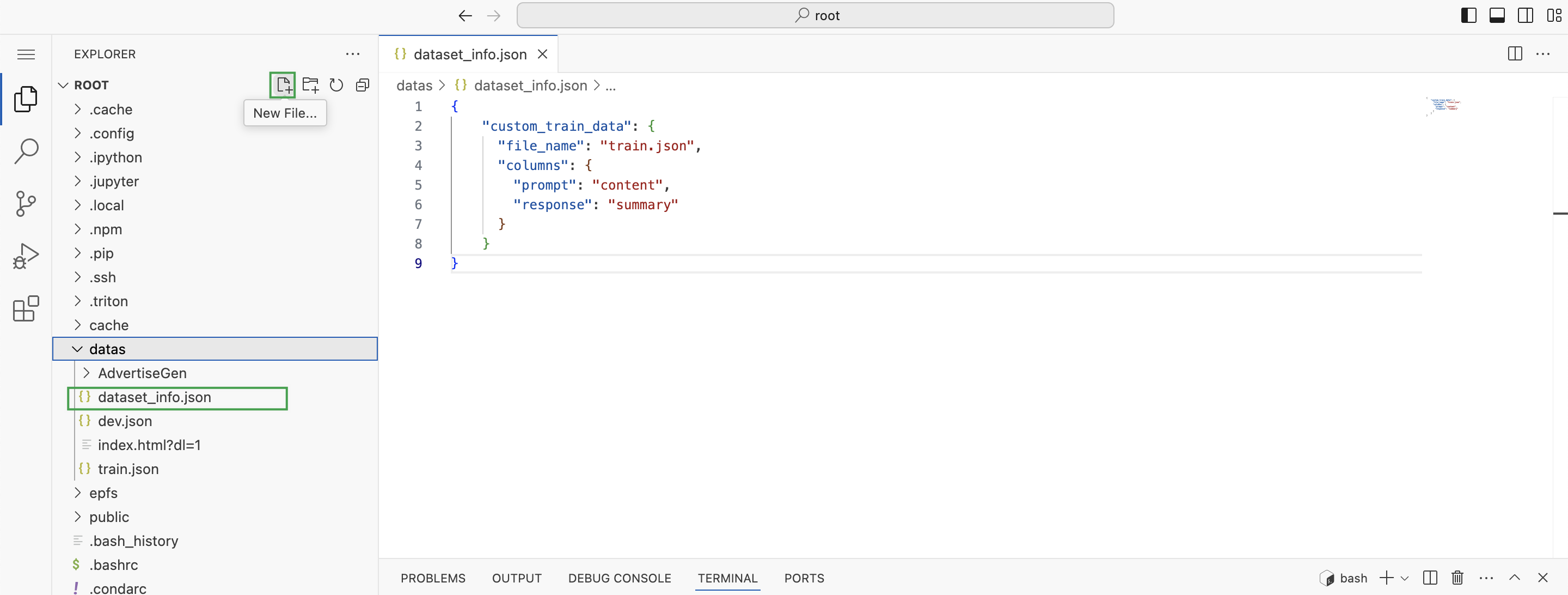
-
选中
root目录,点击 New File 图标,新建名为llama3_lora_sft.yaml的文件,文件内容如下。### model model_name_or_path: public/Llama-3-8B-Instruct # 容器实例创建后会自动挂载预置的模型文件到/root/public文件下,这里我们是用llama3模型 trust_remote_code: true ### method stage: sft do_train: true finetuning_type: lora lora_rank: 8 lora_target: all ### dataset dataset: custom_train_data # 和 /root/datas/dataset_info.json 中的数据集 key对应上 dataset_dir: datas # 数据集文件夹路径 template: llama3 cutoff_len: 2048 max_samples: 1000000 overwrite_cache: true preprocessing_num_workers: 16 dataloader_num_workers: 4 ### output output_dir: saves/llama3-8b/lora/sft2 # 训练输出路径 logging_steps: 10 save_steps: 500 plot_loss: true overwrite_output_dir: true save_only_model: false report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow] ### train per_device_train_batch_size: 2 gradient_accumulation_steps: 8 learning_rate: 1.0e-4 num_train_epochs: 3.0 lr_scheduler_type: cosine warmup_ratio: 0.1 bf16: true ddp_timeout: 180000000 resume_from_checkpoint: null -
在控制台窗口,依次执行如下命令,开始训练,根据上一步配置文件内容,训练结果输出路径为
/saves/llama3-8b/lora/sft2。llamafactory-cli train llama3_lora_sft.yaml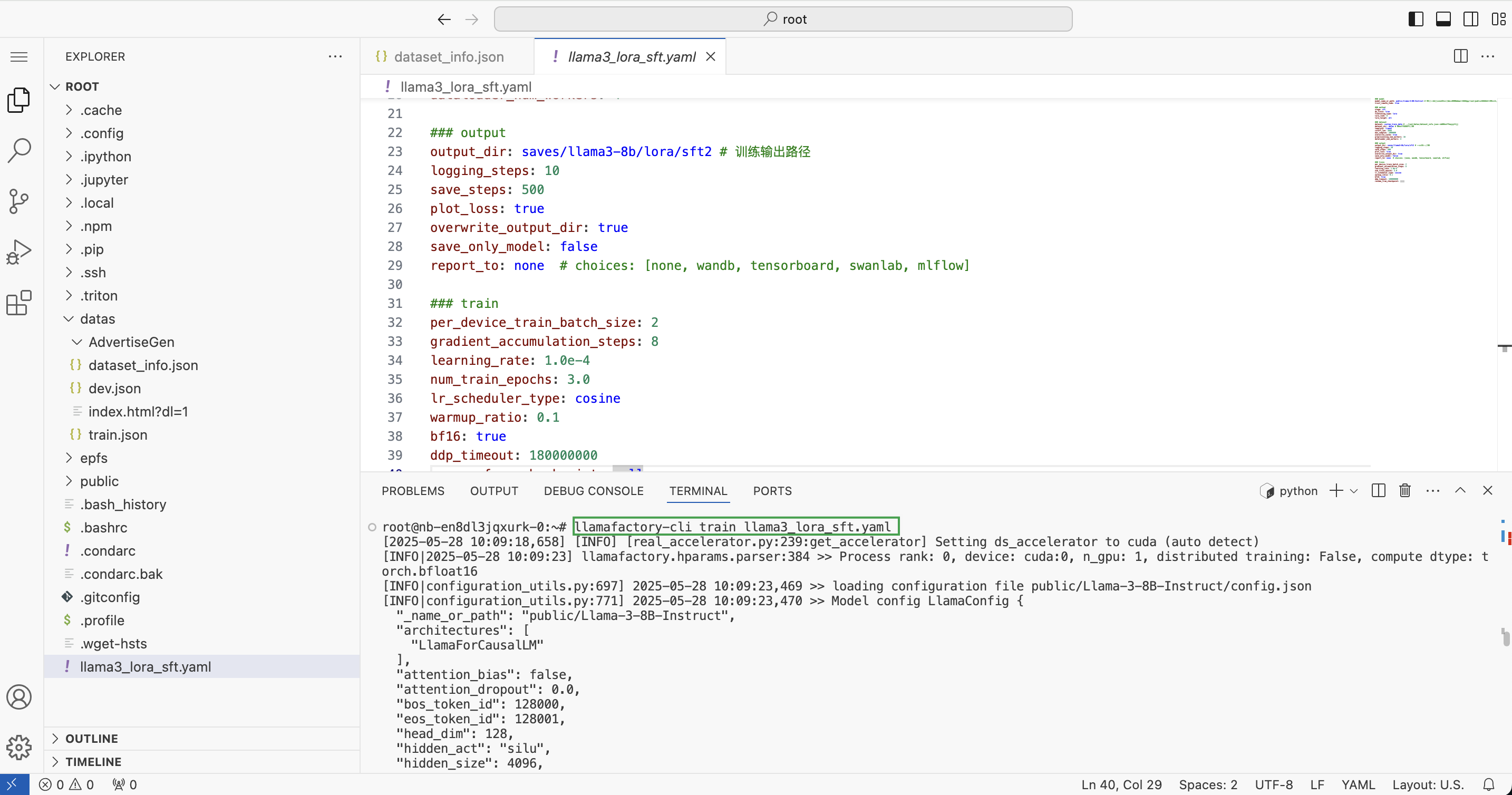
-
等待训练完成,查看
/saves/llama3-8b/lora/sft2路径下的训练结果文件。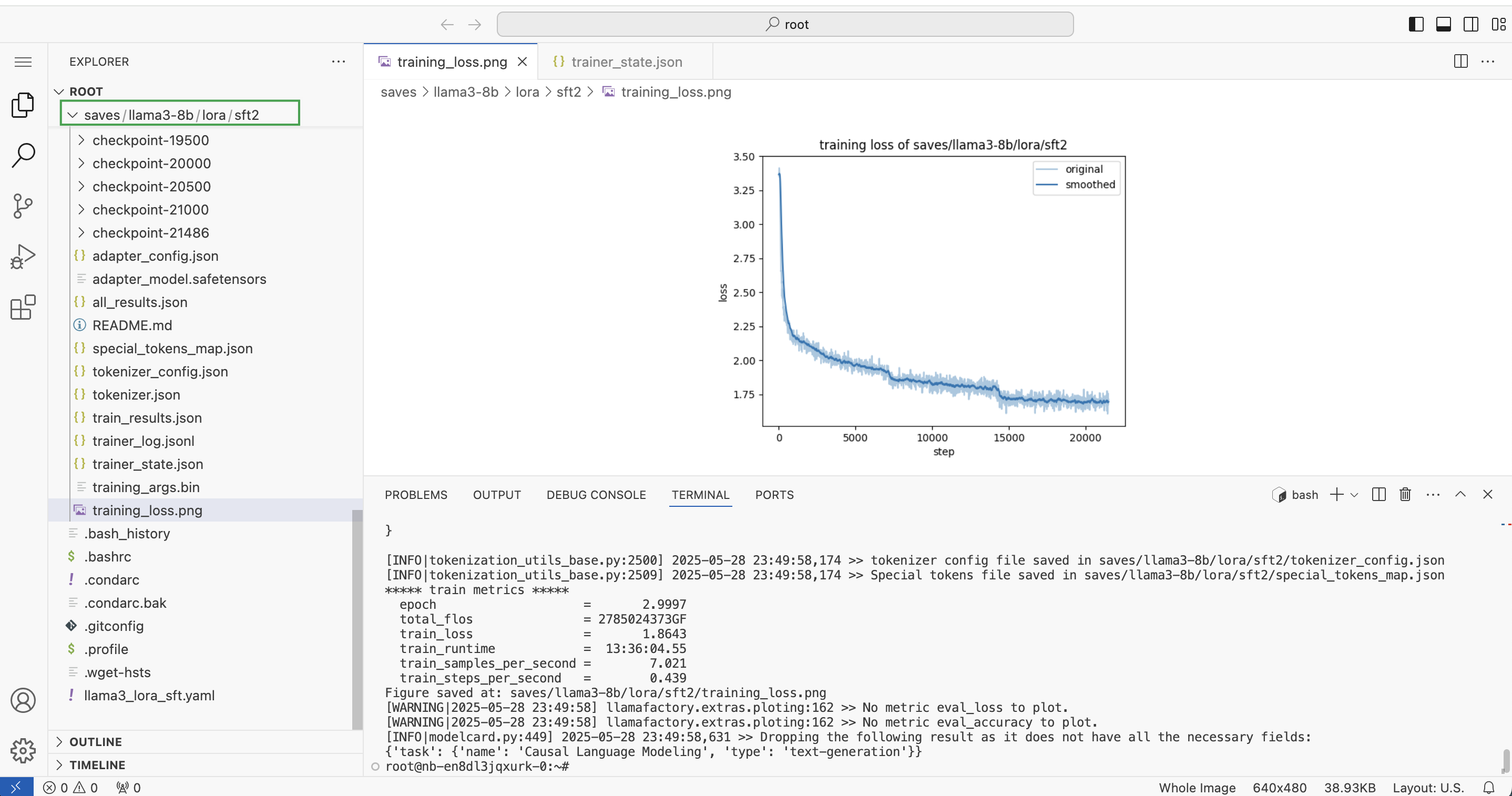
动态合并 LoRA 的推理
-
延续上述操作,待模型训练完成。
-
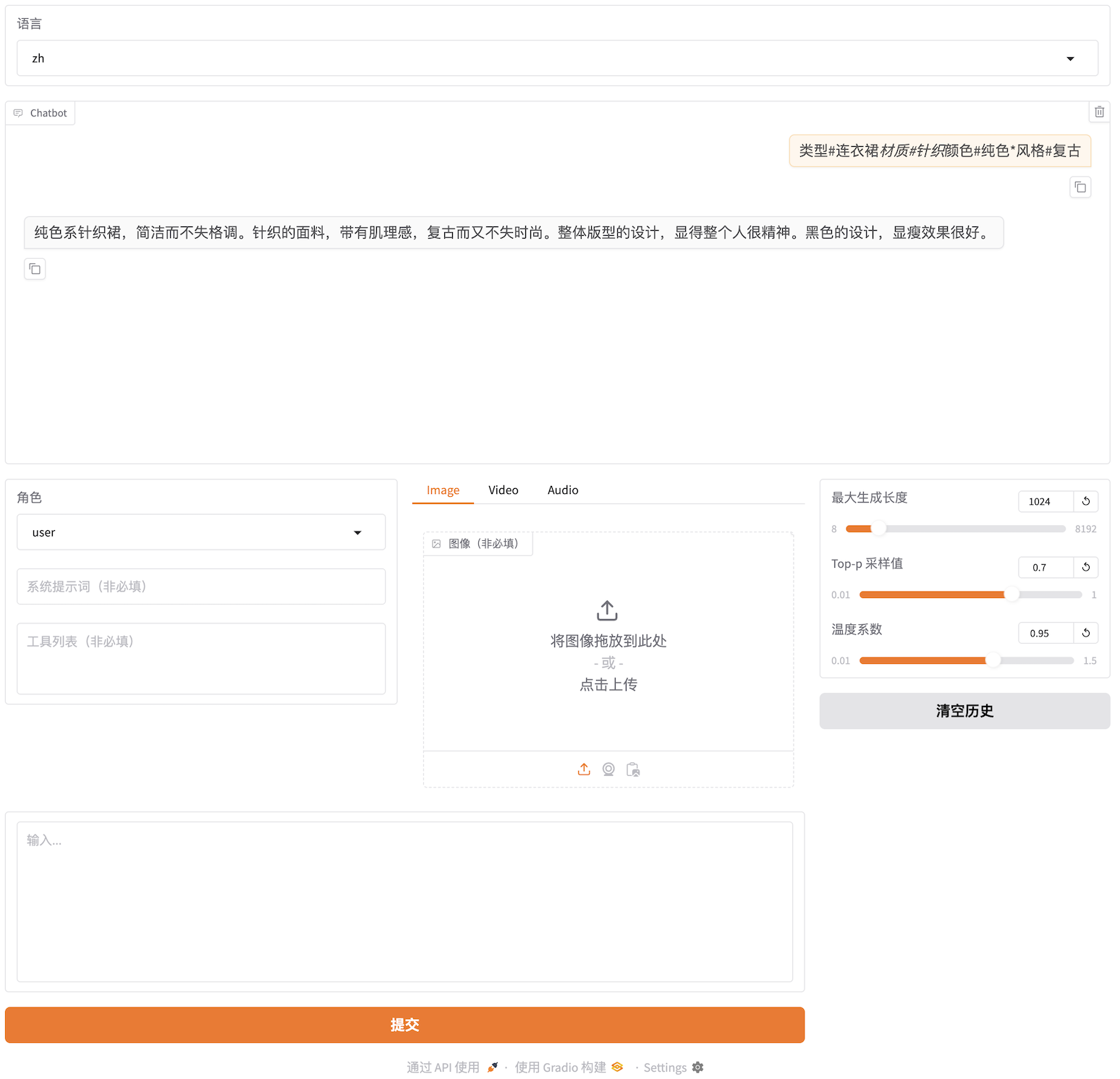
若用户需进行动态验证,可在 vscode UI 的控制台窗口,执行如下命令。
llamafactory-cli webchat --model_name_or_path public/Llama-3-8B-Instruct --adapter_name_or_path saves/llama3-8b/lora/sft2 --template llama3 --finetuning_type lora回显示例:
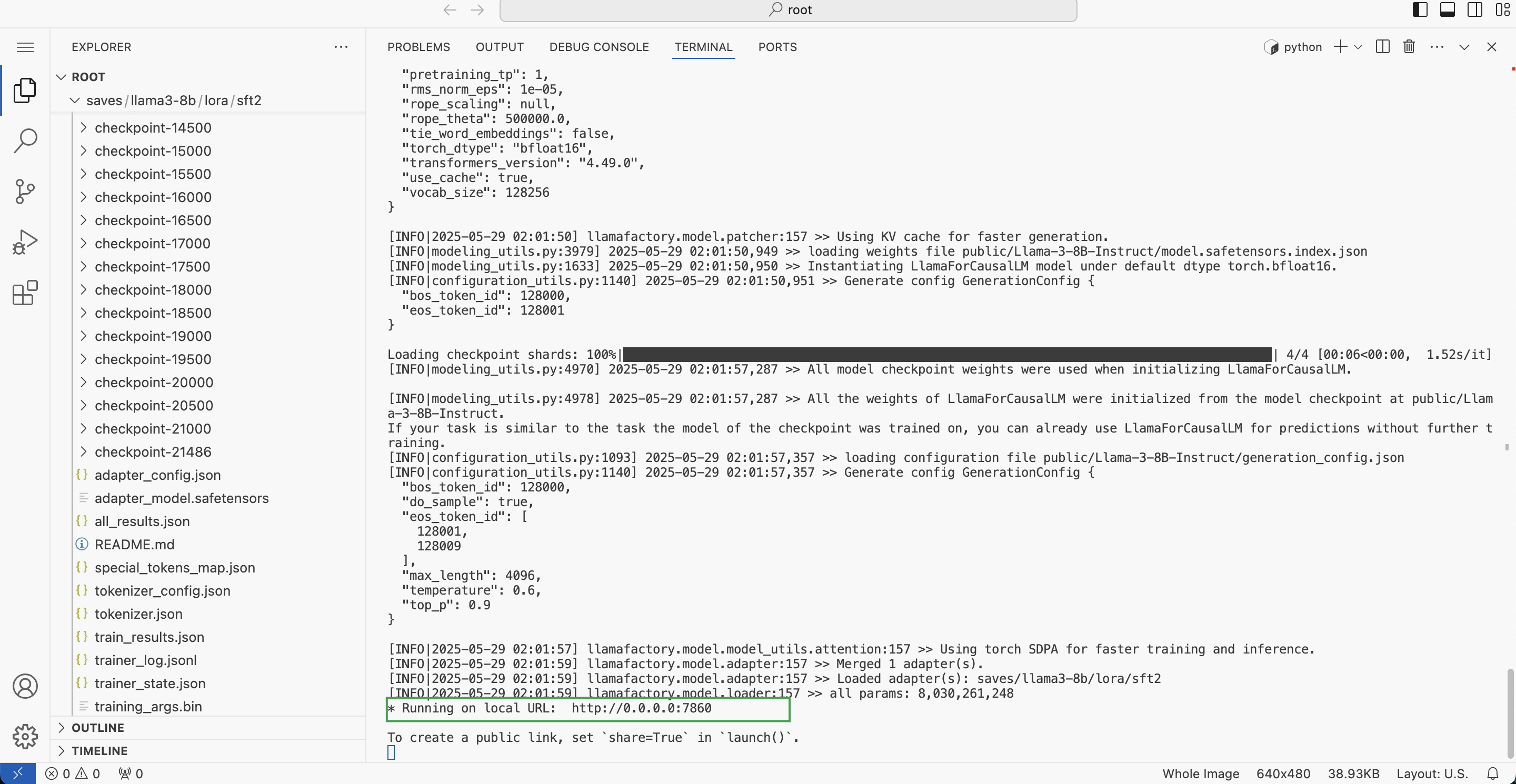
-
由上一步运行结果可知,相应服务运行在
7860端口。用户可返回容器实例表页面,点击更多访问。
-
在弹出更多访问信息窗口中,点击开放端口 > 添加,输入端口号
7860后,点击生成,即可获得相应端口对应的地址。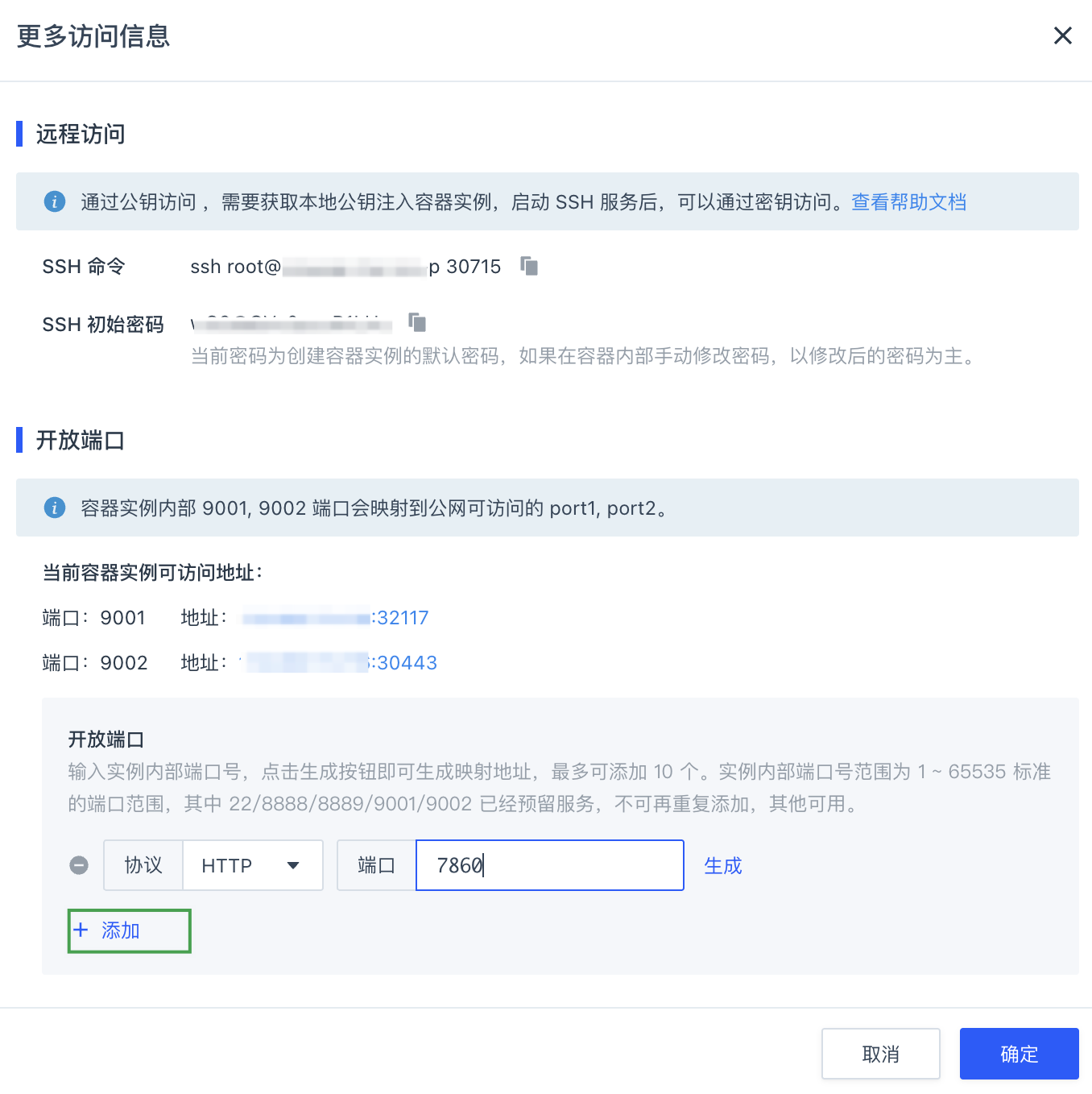
-
点击上一步生成的地址,即可进入相应交互界面。