从 Huggingface 下载模型至容器实例并进行模型部署
本实践旨在介绍如何从 Huggingface 中下载模型到智算平台的容器实例上后进行模型部署。具体操作如下文所示。
环境准备
-
注意 -
根据待下载模型的大小,设置存储配额,避免空间过小导致下载失败。
-
存储目录需创建在
西北三区,以便后续使用。
-
-
创建 Ubuntu 镜像的容器实例,按照如下要求配置参数,点击创建。
-
资源类型:选择西北三区的AMD 12 核 52G的NVIDIA-RTX-4090-D 24G * 1即可。 -
存储与数据:选择上一步创建好的目录即可。 -
镜像:选择基础镜像中的Ubuntu:xb3-dockerhub.coreshub.cn/aicp/public/ubuntu:22.04。 -
其他参数,根据实际情况进行设定即可。
-
-
等待容器实例创建完成,且状态为
运行中。 -
在容器实例列表中,点击相应实例的快捷开发 > jupyter。
说明 -
Jupyter 的使用方法可参考前文内容。
-
用户也可使用其他方式登录容器实例后台。
-
-
在 JupyterLab 页面,打开 Terminal 终端,可查看环境基本信息以及所挂载的存储目录。执行如下命令,可查看 GPU 的状态和信息。
nvidia-smi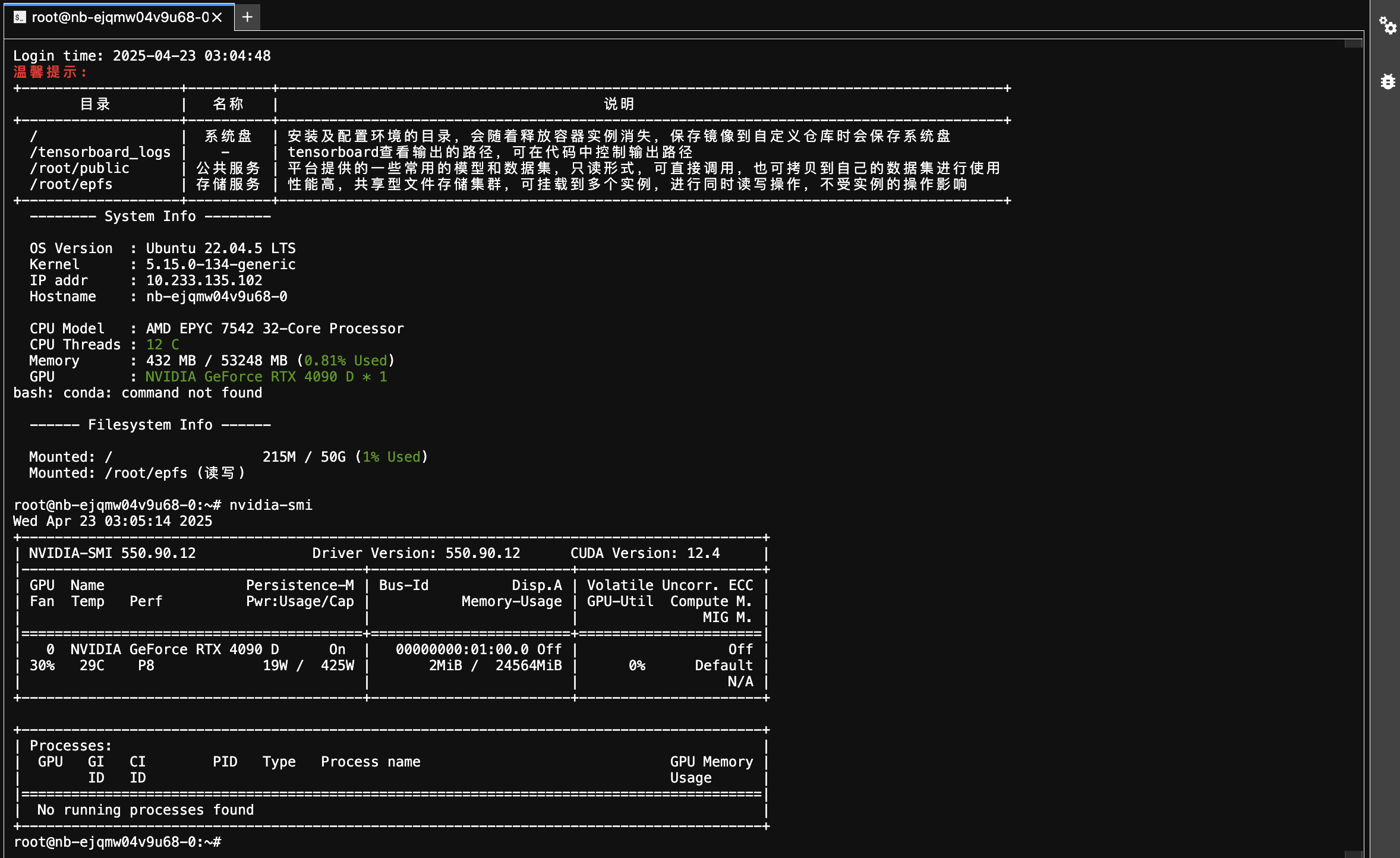
下载模型
-
延续上述操作。
-
执行如下命令,安装 huggingface-cli 下载工具。
pip install -U "huggingface_hub[cli]"
-
以
Qwen/Qwen2.5-VL-3B-Instruct模型为例,依次执行如下操作,将模型下载至/root/epfs目录下。-
设置临时环境变量
HF_ENDPOINT,将 Hugging Face(HF)的默认 API 端点改为国内镜像站hf-mirror.com,以加速模型下载。export HF_ENDPOINT=https://hf-mirror.com -
下载模型。
huggingface-cli download Qwen/Qwen2.5-VL-3B-Instruct --local-dir /root/epfs/Qwen/Qwen2.5-VL-3B-Instruct -
模型下载完成后,可在指定目录下查看。
ls -l /root/epfs/Qwen/Qwen2.5-VL-3B-Instruct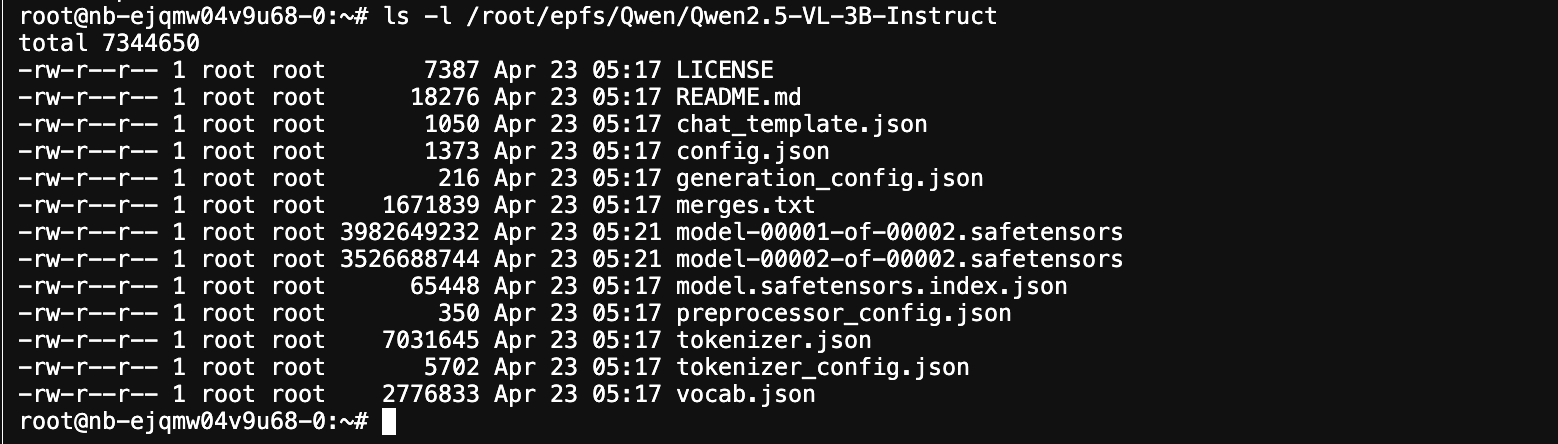
-
启动模型
-
延续上述操作。
-
执行如下命令,安装 uv。
pip install uv -
依次执行如下操作,安装 vLLM。
-
进入 root 目录。
cd /root/ -
执行如下命令,基于 uv 创建一个名为 vllm 的虚拟环境(venv),并指定 Python 3.12 版本,同时包含
--seed参数。uv venv vllm --python 3.12 --seed
注意 执行该操作时,若提示网络无法访问 github.com,则需手动安装 Python 3.12 后,返回
/root/目录,再次执行该操作。手动安装 Python 3.12 具体操作可参考附录。 -
执行如下命令,切换终端会话的 Python 环境到 vllm 虚拟环境。
source vllm/bin/activate -
安装 vLLM。
uv pip install vllm
-
-
执行如下命令,使用 vLLM 启动模型服务。
vllm serve /root/epfs/Qwen/Qwen2.5-VL-3B-Instruct/ --trust-remote-code --disable-log-requests --max-num-seqs 256 -tp 1 --dtype auto --port 9001 --served-model-name Qwen2.5-VL-3B-Instruct --enable-prefix-caching --enable-auto-tool-choice --tool-call-parser hermes回显示例如下,则说明模型服务启动成功:
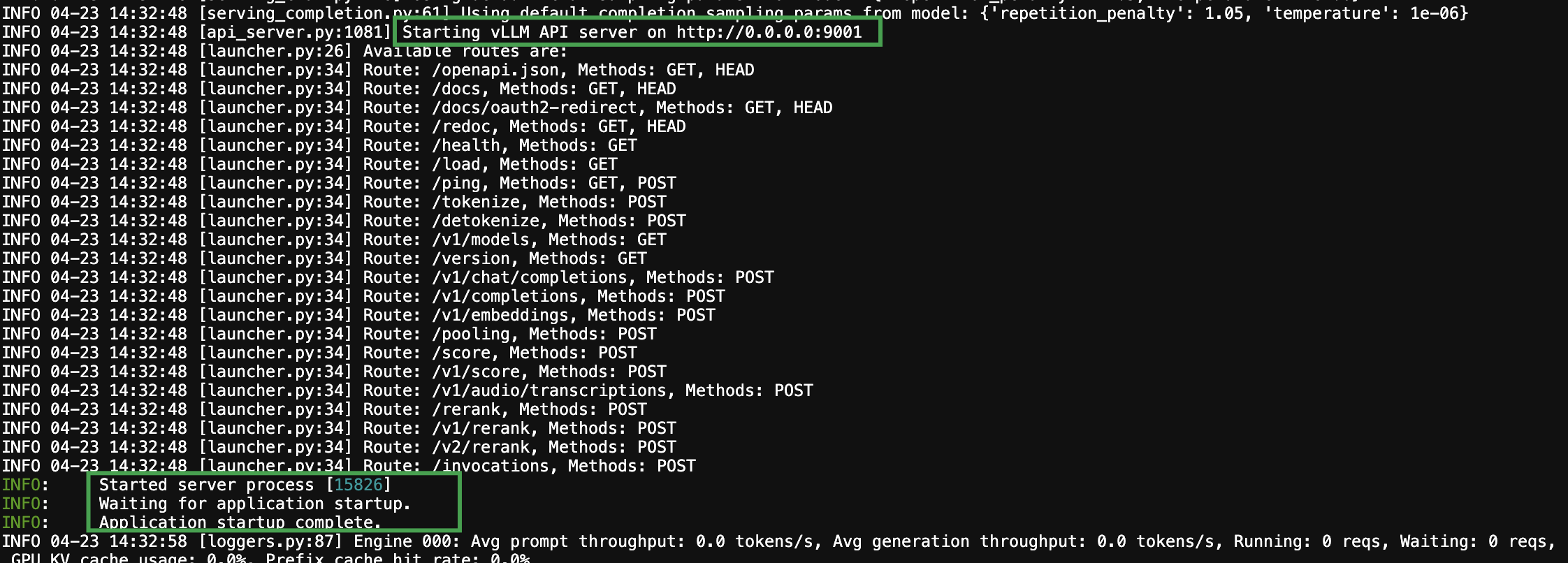
验证模型服务接口
方式一:直接使用 curl 调用
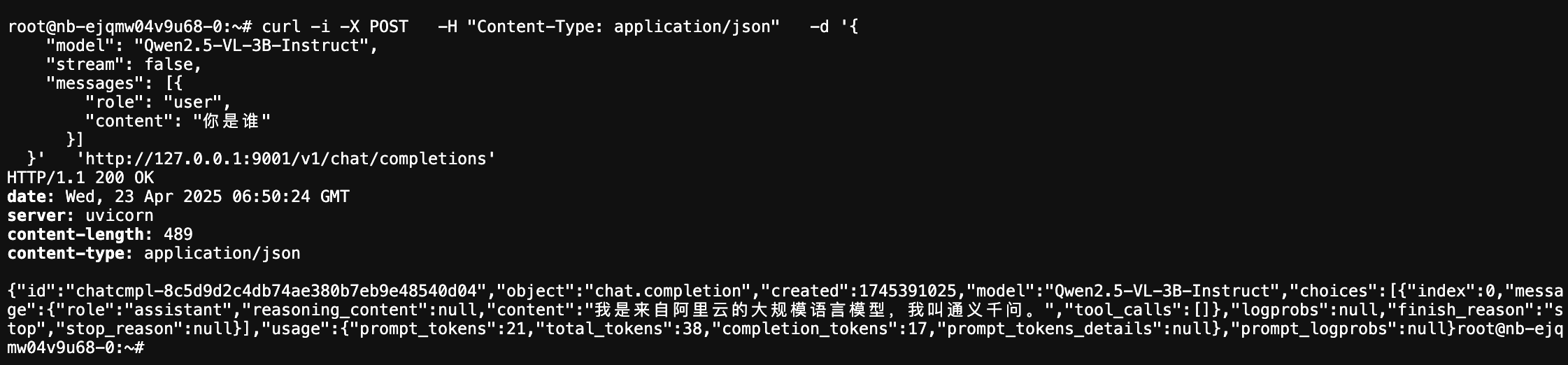
在当前容器实例的 JupyterLab 页面,重新打开一个 Terminal 终端,直接执行如下命令,调用模型接口:
curl -i -X POST -H "Content-Type: application/json" -d '{
"model": "Qwen2.5-VL-3B-Instruct",
"stream": false,
"messages": [{
"role": "user",
"content": "你是谁"
}]
}' 'http://127.0.0.1:9001/v1/chat/completions'回显示例:
方式二:使用个人电脑,调用模型服务
-
返回容器实例列表页面,点击更多访问。

-
在弹出的窗口中,记录 9001 端口所对应的地址。
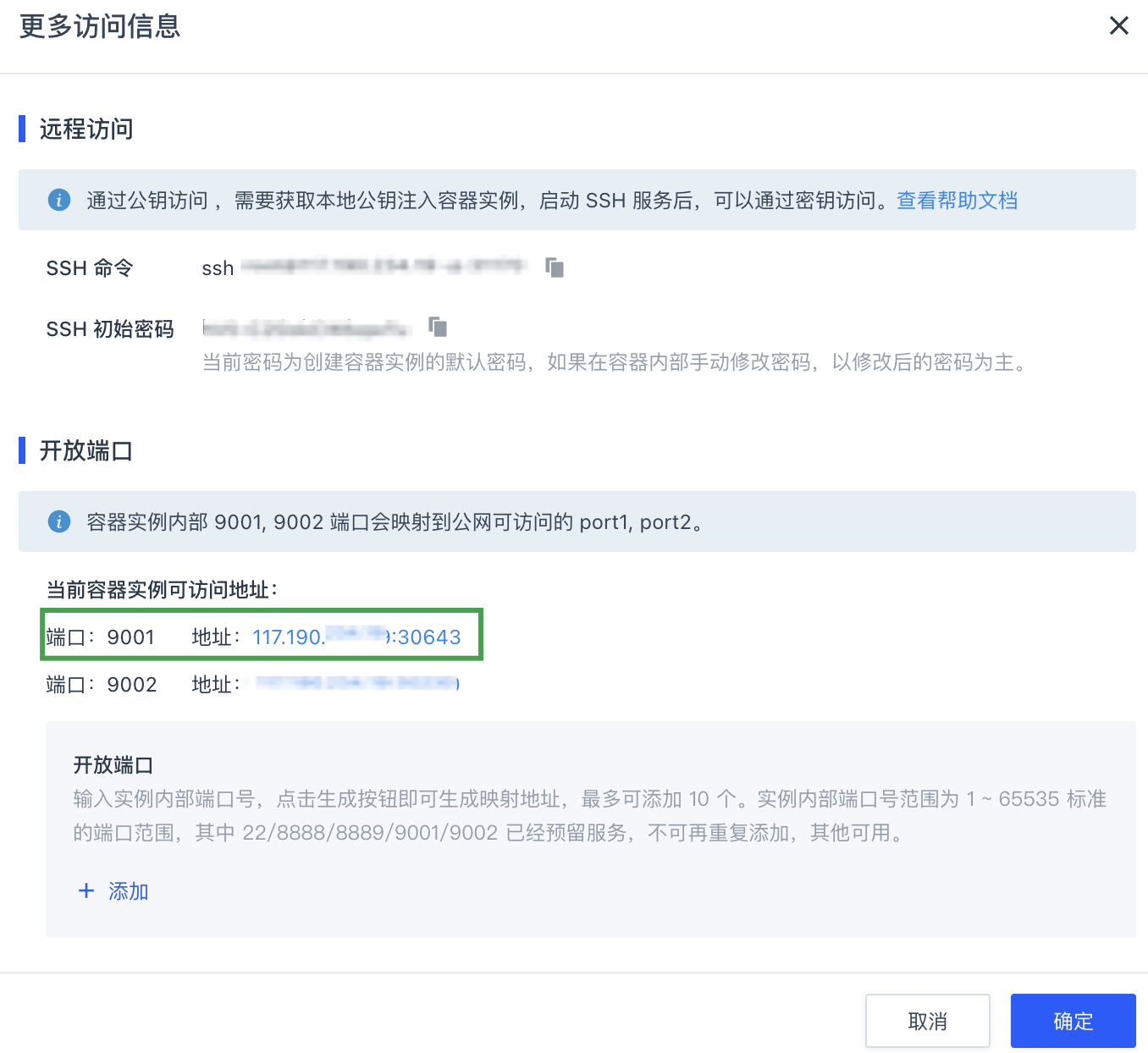
-
开启电脑终端,执行如下如下命令,调用模型接口。
注意 命令行中的
xx.xx.xx.xx:port_1为上一步记录的地址。curl -i -X POST \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen2.5-VL-3B-Instruct", "stream": false, "messages": [{ "role": "user", "content": "你是谁" }] }' \ 'http://xx.xx.xx.xx:port_1/v1/chat/completions'
部署模型并启动推理服务
保存镜像
-
完成上述操作后,表明当前下载的模型可用。
-
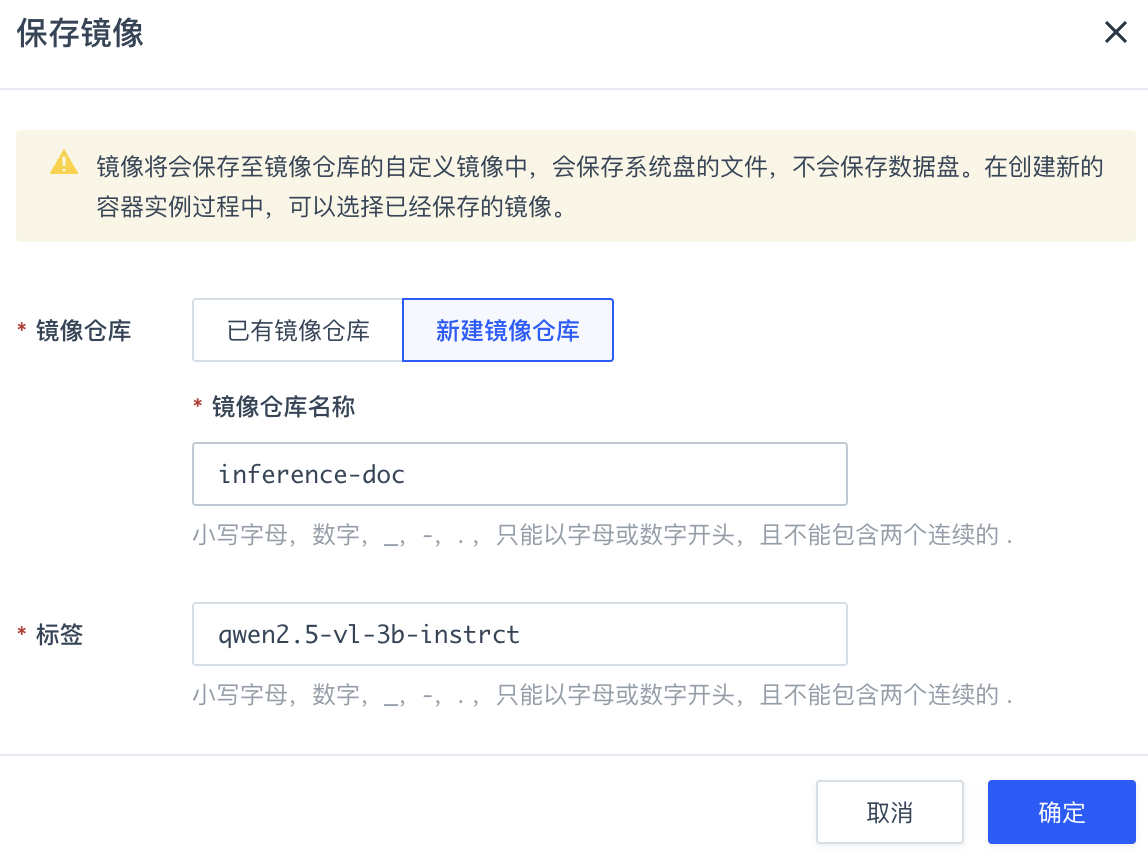
返回容器实例列表页面,点击保存镜像,将安装好 vllm 虚拟环境的容器实例保存为可供使用的镜像。
-
在弹出的窗口中,选择新建镜像仓库,输入镜像仓库名称和标签,点击确定。
-
待镜像保存完成,在左侧导航栏中,选择镜像仓库 > 自定义镜像仓库,新镜像已显示在列。

创建推理服务部署模型
-
在左侧导航栏中,选择模型部署,进入相应页面后,点击 + 推理服务。
-
在创建推理服务页面中,根据如下要求,配置各项参数,点击创建。
-
服务名称:根据实际需要自定义即可,并选择自定义部署。 -
镜像选择:选择自定义镜像,并筛选前文保存的镜像。 -
镜像配置-
模型文件:点击输入框,根据页面提示选择模型文件,此示例为:xb3doc/Qwen/Qwen2.5-VL-3B-Instruct。 -
挂载地址:参考示例填写/root/epfs/Qwen/Qwen2.5-VL-3B-Instruct即可。
-
-
环境变量:保持默认即可。 -
第三方依赖:保持默认即可。 -
启动命令:填写以下命令即可。cd /root/ && source vllm/bin/activate && vllm serve /root/epfs/Qwen/Qwen2.5-VL-3B-Instruct/ --trust-remote-code --disable-log-requests --max-num-seqs 256 -tp 1 --dtype auto --port 9001 --served-model-name Qwen2.5-VL-3B-Instruct --enable-prefix-caching --enable-auto-tool-choice --tool-call-parser hermes -
网络端口:填写9001即可。 -
资源规格:选择AMD 12核 52G、NVIDIA-RTX-4090-D 24G * 1即可。
-
-
等待推理服务创建成功,状态为
运行中,点击推理服务名称,进入其详情页,选择服务日志页签,日志内容如下,则说明模型部署并启动成功。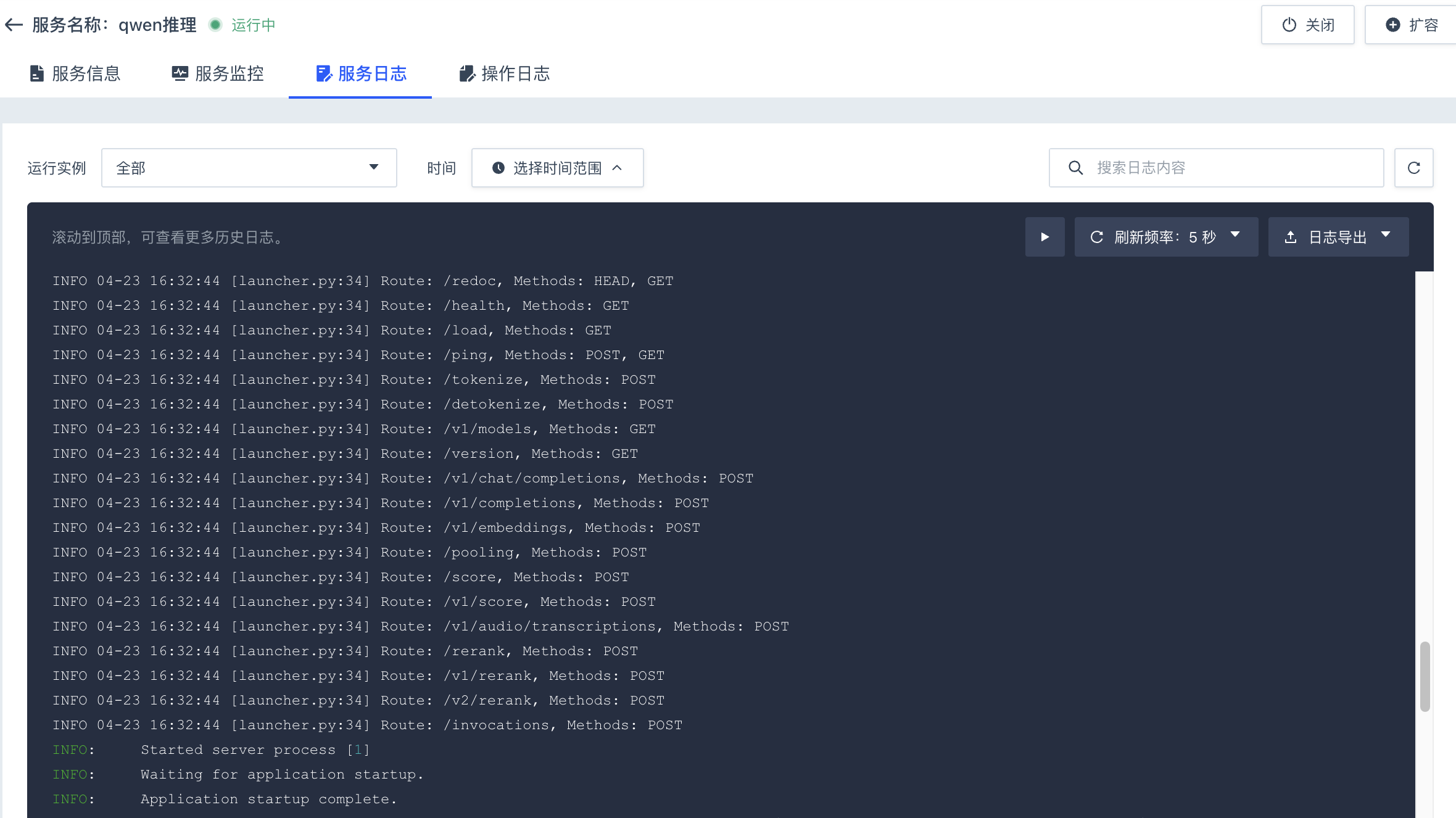
验证推理服务
-
在推理服务详情页面,选择服务信息页签,记录访问地址的外网 URL 和 API 密钥。
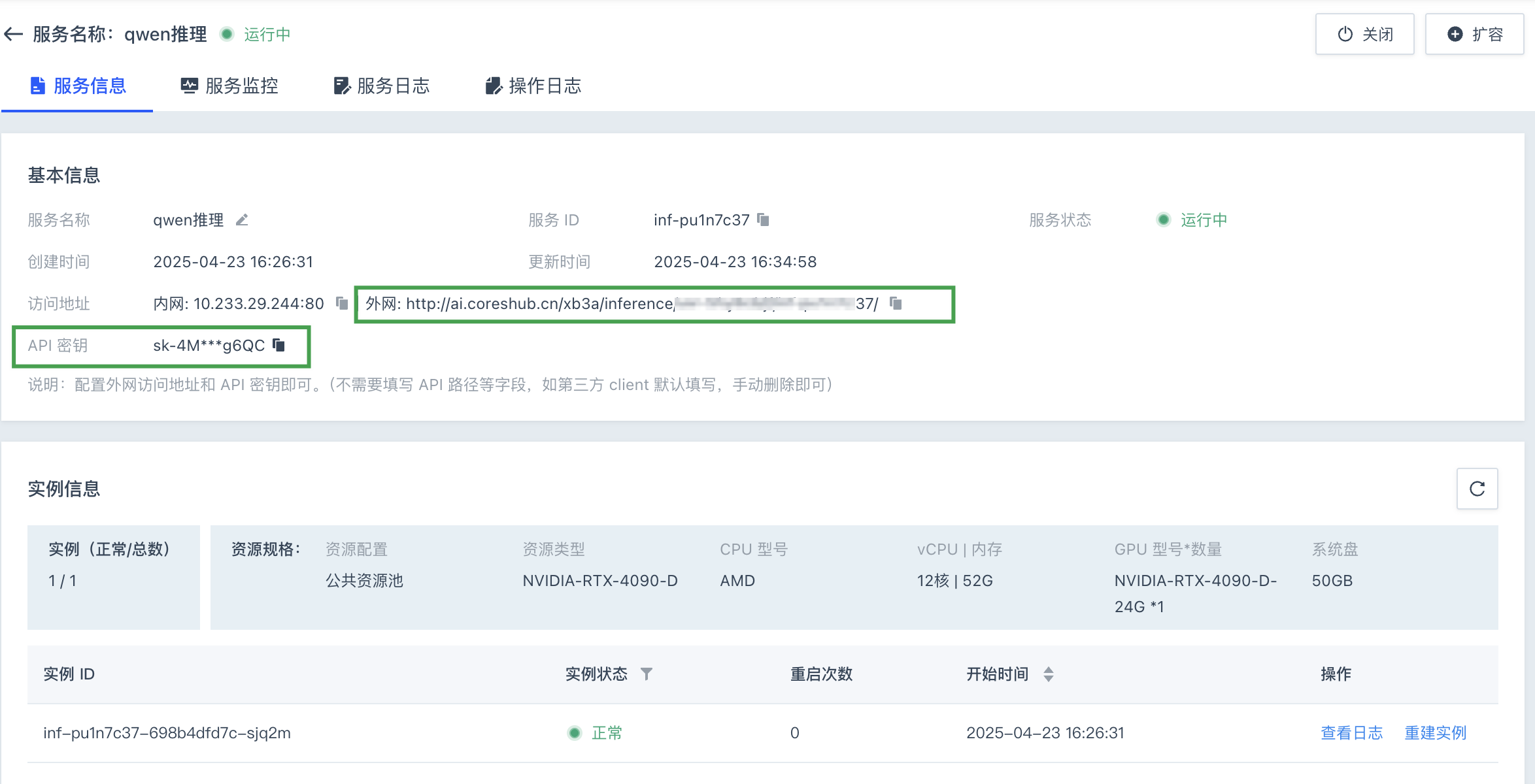
-
打开个人电脑终端,执行如下命令,调用模型接口。
curl -i -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Bearer sk-xxxxxxxxxx" \ -d '{ "model": "Qwen2.5-VL-3B-Instruct", "stream": false, "messages": [{ "role": "user", "content": "你是谁" }] }' \ 'http://ai.coreshub.cn/xb3a/inference/xxxxxxxx/xxxxxxx/v1/chat/completions'回显示例:
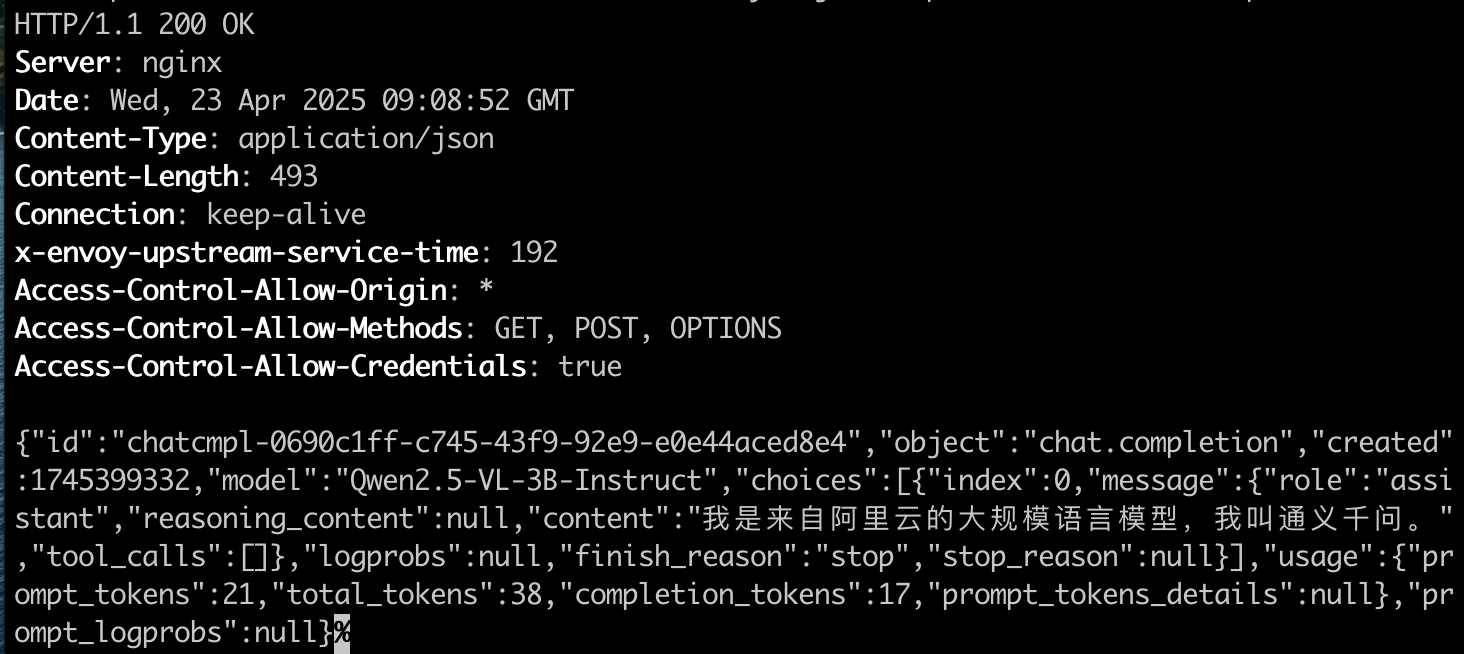
-
sk-xxxxxxxxxx:为上一步记录的 API 秘钥。 -
http://ai.coreshub.cn/xb3a/inference/xxxxxxxx/xxxxxxx/:为上一步记录的外网访问地址。
-
-
推理服务其他验证方式,可参考模型调用相关内容。
附录
用户可依次执行如下命令,下载并安装 Python 3.12。
# apt-get install build-essential gdb lcov pkg-config \
libbz2-dev libffi-dev libgdbm-dev libgdbm-compat-dev liblzma-dev \
libncurses5-dev libreadline6-dev libsqlite3-dev libssl-dev \
lzma lzma-dev tk-dev uuid-dev zlib1g-dev libmpdec-dev
# wget https://www.python.org/ftp/python/3.12.9/Python-3.12.9.tgz
# tar -xzvf Python-3.12.9.tgz
# cd Python-3.12.9
# ./configure --prefix=/usr/local/python3.12/
# make
# make install
# cp /usr/local/python3.12/bin/python3.12 /usr/local/bin